Archive
A Custom Drawing Projections Tool
Back in 2007 I developed a software tool that could generate technical drawings in a range of drawing projections from a 3D model with emphasis on oblique (both cabinet and cavalier, as well as custom obliques), planometric, dimetric, trimetric and one-point perspective.
I could describe them all as well as many more in terms of what the projected three axis look like on the projection plane. I described them all in terms of a scale on each of the three axis, as well as the angle two of the axis make with the projection plane’s horizontal.

Description of the projection in terms of the projected view of the three standard basis.
In terms of the actual development of the program I’m sure I could have done things a lot better. But I did learn a lot from the experience. The program worked to my needs and did what I wrote it to do so in that sense it was a success. The only downside would be that I did a lot of code rewriting of code that already existed out there (which probably did thinks better than I implemented them). Although since then I have done much more programming and had formal training so have learnt about better methods and practices.
The approach I took was basically import a DXF file, process the data to change its projection, and then export it as a DXF again. I used 3D polylines generated from my 3D model in Rhino and saved as DXF for the input. So I had to write a cutdown DXF reader/writer, as well as a way of storing this data internally and then doing the transformations on it then exporting it back into DXF so I could open it up in AutoCAD.
I only supported points, polylines, circles and arcs as this is basically all that Rhino exported from my model. To simplify the process of circles and arcs I internally converted them to a bunch of polylines as only for some projections they stayed as nice ellipses.

The user interface of the tool.
From a very simple model in Rhino, I use the silhouette tool to create the polylines which once impororted into my program produced the following samples.

Cabinet Oblique

Cavalier Oblique

Planometric

One Point Perspective
There is also a range of built in axonometric projections…

A range of axonometric projections are built in.
Finally here are some of my production drawings (from my 2007 HSC ITG Major Work (photos here)) that I used the software to create.

Oblique

One Point Perspective

Planometric

Trimetric
The Mathematics Behind Graphical Drawing Projections in Technical Drawing
In the field of technical drawing, projection methods such as isometric, orthogonal, perspective are used to project three dimensional objects onto a two dimensional plane so that three dimensional objects can be viewed on paper or a computer screen. In this article I examine the different methods of projection and their mathematical roots (in an applied sense).
The approach that seems to be used by Technical Drawing syllabuses in NSW to draw simple 3D objects in 2D is almost entirely graphical. I don’t think you can say this is a bad thing because you don’t always want or need to know the mathematics behind the process, you just want to be able to draw without thinking about this. However to have an appreciation of what’s really happening the mathematical understanding is a great thing to learn.
Many 3D CAD/CAM packages available on the market today (such as AutoCAD, Inventor, Solidworks, CATIA, Rhinoceros) can generate isometric, three point perspective or orthogonal drawings from 3D geometry, however from what I’ve seen they can’t seem do other projections such as dimetric, trimetric, oblique, planometric, one and two point perspective. Admittedly I don’t think these projections are any use or even needed, but when your at high school and you have to show that you know how do to oblique, et al. it can be a problem when the software cannot do it for you from your 3D model. (So I actually wrote a small piece of software to help with this in this article). But to do so, I needed to understand the mathematics behind these graphical projections. So I will try to explain that here.
The key idea is to think of everything having coordinates in a coordinate system (I will use the Cartesian system for simplicity). We can then express all these projections as mathematical transformations or maps. Like a function, you feed in the 3D point, and then you get out the projected 2D point. Things get a bit arbitrary here because an isometric view is essentially exactly the same as a front view. So we keep to the convention that when we assign the axis of the coordinate system we try to keep the three planes of the axis parallel to the three main planes of the object.

The three "main" planes of the object are placed parallel to the three planes of the axis. This is how we will choose our axis in relation to the object.
We will not do this though,

We will not choose it like this...

...or this.
In fact doing something like that shown just above with the object rotated is how we get projections like isometric.
Now what we do is take the coordinates of each point and “transform” them to get the projected coordinates, and join these points with lines where they originally were. However we can only do this for some kinds of projections, indeed for all the ones I have mentioned in this post this will do but only because these projections have a special property. They are linear maps (affine maps also hold this property and are a superset of the set of linear maps) which means that straight lines in 3D project to straight lines in 2D.
For curves we can just project a lot of points on the curve (subdivide it) and then join them up after they are projected. It all depends what our purpose is and if we are applying it practically. We can generate equations of the projected curves if we know the equation of the original curve but it won’t always be as simple. For example circles in 3D under isometric projection become ellipses on the projection plane.
Going back to the process of the projection, we can use matrices to represent these projections where

is the same as,

We call the 3 by 3 matrix above as the matrix of the projection.
Knowing all this, we can easily define orthogonal projection as you just take two of the dimensions and cull the third. So for say an orthographic top view the projection matrix is simply,
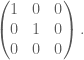
Now we want a projection matrix for isometric. One way would be to do the appropriate rotations on the object then do an orthographic projection, we can get the projection matrix by multiplying the matrices for the rotations and orthographic projection together. However I will not detail that here. Instead I will show you another method that I used to describe most of the projections that I learnt from high school (almost all except perspectives).
I can describe them as well as many “custom” projections in terms of what the three projected axis look like on the projection plane. I described them all in terms of a scale on each of the three axis, as well as the angle two of the axis make with the projection plane’s horizontal.

Projection attributes described in terms of the projected axis.
Using this approach we can think of the problem back in a graphical perspective of what the final projected drawing will look like rather than looking at the mathematics of how the object gets rotated prior to taking an orthographic projection or what angle do the projection lines need to be at in relation to the projection plane to get oblique, etc. Note also that the x, y, z in the above diagram are the scales of the x, y, z axis respectively. So we can see in the table below that we can now describe these projections in terms of a graphical approach that I was first taught.
| Projection | α (alpha) | β (beta) | Sx | Sy | Sz |
| Isometric | 30° | 30° | 1 | 1 | 1 |
| Cabinet Oblique | 45° | 0° | 0.5 | 1 | 1 |
| Cavalier Oblique | 45° | 0° | 1 | 1 | 1 |
| Planometric | 45° | 45° | 1 | 1 | 1 |
Now all we need is a projection matrix that takes in alpha, beta and the three axes scale’s and does the correct transformation to give the projection. The matrix is,

Now for the derivation. First we pick a 3D Cartesian coordinate system to work with. I choose the Z-up Left Hand Coordinate System, shown below and we imagine a rectangular prism in the 3D coordinate system.

Block in 3D coordinate system.
Now we imagine what it would look like in a 2D coordinate system using isometric projection.

Block in 2D coordinate system (isometric).
As the alpha and beta angles (shown below) can change, and therefore not limited to a specific projection, we need to use alpha and beta in the derivation.
Now using these simple trig equations below we can deduce the following.

All the points on the xz plane have y = 0. Therefore the x’ and y’ values on the 2D plane will follow the trig property shown above, so:

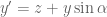
However not all the points lie on the xz plane, y is not always equal to zero. By visualising a point with a fixed x and z value but growing larger in y value, its x’ will become lower, and y’ will become larger. The extent of the x’ and y’ growth can again be expressed with the trig property shown, and this value can be added in the respective sense to obtain the final combined x’ and y’ (separately).
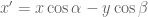
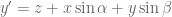
If y is in the negative direction then the sign will automatically change accordingly. The next step is to incorporate the scaling of the axes. This was done by replacing the x, y & z with a the scale factor as a multiple of the x, y & z. Hence,

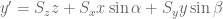
This can now easily be transferred into matrix form as shown at the start of this derivation or left as is.
References:
Harvey, A. (2007). Industrial Technology – Graphics Industries 2007 HSC Major Project Management Folio. (Link)
An Introduction to Hypercubes.
Point, Line Segment, Square, Cube. But what comes next, what is the equivalent object in higher dimensions? Well it is called a hypercube or n-cube, although the 4-cube has the special name tesseract.
Construction Methods
Before I go on to explain about the elements of hypercubes, let me show you some pictures of some hypercubes. I guess this also raises the question how can you construct these objects. One method is to start with a point. Then stretch it out in one dimension to get a line segment. Then take this line and stretch it out in another dimension perpendicular to the previous one, to get a square. Then take that square and stretch it out in another dimension perpendicular to the previous two to get a cube. This is when your visualisation may hit a wall. Its very hard to then visualise taking this cube and stretching it in another dimension perpendicular to the previous three. However mathematically, this is easy and this is one approach to constructing hypercubes.

We place a point in R3.

...and then stretch the point in one dimension to make a line...

...and then we stretch that line in a direction perpendicular to the previous time...

...and finally stretch that plane in a direction perpendicular the the previous two times.
However there is more mathematical and analytical method. You most probably know that these n-cubes have certain elements to them, namely vertices (points), edges (lines), faces (planes), and then in the next dimension up, cells and then in general n-faces. These elements are summed up nicely here. Firstly we take a field of say 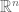
There is a vertex described by each vector 
There is an edge between vertices 

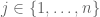
There is an m-face between (or though) vertices 
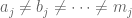

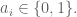

Basically this means we list the vertices just as if were were counting in base 2. And then we can group these vertices into different groups based on the n-face level and (if we think of the vertices of a bit string) how many bits we have to change to make two vertices bit streams the same. This approach is very interesting because the concept of grouping these vertices relates strongly to hypergraphs.
Another way to think about it is as follows. Edges, from the set of all edges (i.e. joining each vertex with every other vertex), are the ones that are perpendicular to one of the standard basis vectors. This generalises to n-faces; from the set of all n-faces (i.e. all ways of grouping vertices into groups of n) are those that the object constructed is parallel to the span of any set of n of the standard basis vectors.
When you think about it, a lot of things that you can say about the square or cube generalise. For instance you can think of a square being surrounded by 4 lines, and cube by 6 surfaces, a tesseract by 8 cells, etc.
Visualisation Methods
Now that we have some idea how to describe and build n-cubes, the next question is how do we draw them. There are numerous methods and I can’t explain them all in this post (such as slicing and stereographic projection, as well as other forms of projection (I’ll leave these for another blog article)). But another question is also what aspects do we draw and how do we highlight them. For instance it may seem trivial in two dimensions to ask do I place a dot at each vertex and use just 4 solid lines for the edges. But in higher dimensions we have to think about how do we show the different cells and n-faces.
Firstly, how can we draw or project these n dimensional objects in a lower dimensional world (ultimately we want to see them in 2D or 3D as this is the only space we can draw in). This first method is basically the exact same approach that most people would have first learnt back in primary school. Although, I do not think it makes the most sense or makes visualisation easiest. Basically this method is just the take a dot and perform a series of stretches on it that I described earlier, although most people wouldn’t think this is what they were doing. Nor would we usually start with a dot, we would normally start with the square. Although we will, so we start with this.

0-cube.
We would now draw a line along some axis from that dot, and place another dot at the end of this line.

1-cube, showing vertices and edges.
Now from each of the dots we have, we would draw another line along some other axis and again draw a dot at the end of each of those two lines. We would then connect the newly formed dots.

2-cube, showing vertices and edges.
Now, we just keep repeating this process where by each time we are drawing another dimension. So we take each of these four dots and draw lines from them in the direction of another axis, placing a dot at the end of each of these lines, and joining each of the dots that came from other dots that were adjacent, with a line.

3-cube, showing vertices and edges.
Now for 4D and beyond we basically keep the process going, just choosing really anywhere from the new axis, so long as it passes though the origin.

4-cube, showing vertices and edges.
If we do a little bit of work we can see that this map is given by the matrix,

where 
Now this method seems very primitive, and a much better approach is to use all the dimensions we have. We live in a three dimensional world, so why just constrict our drawings to two dimensions! Basically, an alternate approach to draw an n-cube in three dimensional space would be to draw n lines all passing though a single point. Although it is not necessary to make all these lines as spread out as possible, we will try to. (This actually presents another interesting idea of how do we equally distribute n points on a sphere. For instance we can try to make it so that all the angles between any two of the points and the origin are equal. But I will leave this for another blog article later.) We then treat each of these lines as one dimension from there we can easily draw, or at least represent an n-dimensional point in 3D space. Now obviously we can have two different points in 4D that map to the same 3D point, but that is always going to happen no matter what map we use. The following set of 4 vectors are the projected axis we will use as a basis.
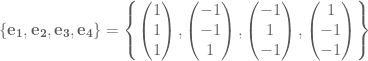
Now I won’t say how I got these (actually I took them from Wikipedia, they are just the vertices of a 3-simplex) but all of the vectors share a common angle between any two and the origin.
Now if we draw in our tesseract, highlighting the cells with different colours (not this became problematic with some faces and edges as they are a common boundary for two different faces, so you cannot really make them one colour or the other) we get something like this,

Tesseract projected onto R3. The cells are shown in different colours, the purple lines show the four axis.
The projection matrix for this projection is then simply (from the vectors that each of the standard basis maps to),

Now if we compare this to our original drawing (note I’m not talking about the projection used, but rather the presentation of the drawings, i.e. the colour.) I think you will see that the second one is clearer and try’s to show where the cells and faces are, not just the vertices and edges. Note also the second one is in 3D so you can rotate around it. Looking at the first one though, you will notice it doesn’t show where the faces or cells are. Remember that we have more than just vertices, edges and faces. We have cells, and n-faces. These are essentially just different groupings of the vertices. But how can we show these. Now the most mathematical way would be to just list all the different groupings. This is okay, but I like to see things in a visual sense. So another way would just show different elements. Like you draw all the vertices on one overhead, edges on another, and so on. Then when you put all these overheads on top of each other we get the full image, but we can also look at just one at a time to see things more clearly. This would be particularly more useful for the higher dimensional objects and higher dimensional elements. We can also use different colours to show the different elements. For example in the square, we can see that the line around surrounding it is 4 lines, but in higher dimensions its not so easy, so we can colour the different parts to the element differently. (When I say part I mean the 4 edges of a square are 4 different parts. Whereas the edges are all one element, but are a different element to the vertices.)
Some Interesting Properties
Once you start defining hypercubes there are many interesting properties that we can investigate. For this section lets just assume that we have the standard hypercube of side length 1. Now we can trivially see that the area, volume, etc. for the respective hypercube will always be 1. As described above each time we add another dimension and sweep the object out into that dimension we effectively multiply this hypervolume by 1. So for an n-cube, the hypervolume of it will be 
The next obvious question to ask is what is the perimeter, surface area, cell volume, …, n-face hypervolume of the respective n-cube? It gets a little confusing as you have to think about what exactly you are finding. Is it a length, an area, a volume? Well it will just be an (n – 1) volume. Eg. in 2D we are finding a length (the perimeter), in 3D, an area (surface area), and so on so that each time we increase the dimension of the n-cube we increase the units we are measuring in. Well if we just start listing the sequence (starting with a square), 4, 6… we notice this is just the number of (n – 1) degree elements. Namely, the number of edge, faces, cells, etc.
This leads me in the obvious question of how can I calculate the number of m-elements of the n-cube?
Well instead of me just going to the formula, which you can find on Wikipedia anyway, I will go though my lines of thinking when I first tried to work this out. Number of vertices is easy, each component of the n-vector can be either a 0 or a 1. So for each component there is 2 possibilities, but we have n of them, so it is just 2x2x2… n times, or 2n. Now originally when I tried to work out the number of edges, I started listing them and saw that I could construct the recurrence… Although with the help of graph theory it is very simple. In graph theory the handshaking theorem says 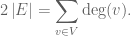



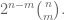
(I shall try to write more at a later date.)
References:
- Hypercube. (2008, October 14). In Wikipedia, The Free Encyclopedia. Retrieved 08:19, October 21, 2008, from http://en.wikipedia.org/w/index.php?title=Hypercube&oldid=245242295
- Tran, T., & Britz, T. (2008). MATH1081 Discreet Matematics: 5 Graph Theory.
(x,y,z,w) in OpenGL/Direct3D (Homogeneous Coordinates)
I always wondered why 3D points in OpenGL, Direct3D and in general computer graphics were always represented as (x,y,z,w) (i.e. why do we use four dimensions to represent a 3D point, what’s the w for?). This representation of coordinates with the extra dimension is know as homogeneous coordinates. Now after finally getting formally taught linear algebra I know the answer, and its rather simple, but I’ll start from the basics.
Points can be represented as vectors, eg. (1,1,1). Now a common thing we want to do in computer graphics is to move this point (translation). So we can do this by simply adding two vectors together,
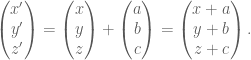
If we wanted do some kind of linear transformation such as rotate about the origin, scale about the origin, etc, then we could just multiply a certain matrix with the point vector to obtain the image of the vector under that transformation. For example,
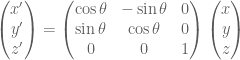
will rotate the vector (x,y,z) by angle theta about the z axis.
However as you may have seen you cannot do a 3D translation on a 3D point by just multiplying a 3 by 3 matrix by the vector. To fix this problem and allow all affine transformations (linear transformation followed by a translation) to be done by matrix multiplication we introduce an extra dimension to the point (denoted w in this blog). Now we can perform the translation,

by a matrix multiplication,
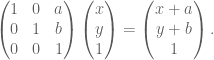
We need this extra dimension for the multiplication to make sense, and it allows us to represent all affine transformations as matrix multiplication.
REFERENCES:
Homogeneous coordinates. (2008, September 29). In Wikipedia, The Free Encyclopedia. Retrieved 04:33, September 29, 2008, from http://en.wikipedia.org/w/index.php?title=Homogeneous_coordinates&oldid=241693659
 Google Reader Shared Items
Google Reader Shared Items
- An error has occurred; the feed is probably down. Try again later.
License

The content on this blog by Andrew Harvey, unless otherwise noted is licensed under a Creative Commons Attribution-Share Alike 3.0 Australia License.
