Archive
Using exiftool to reduct EXIF metadata in some JPEGs
After spending way to much time trying to edit some EXIF metadata in some JPEG photographs, I’m posting my method here for future reference.
The first thing I needed to do was geoencode/geotag the images with a GPS location tag. I did this with the perl module Image::ExifTool::Location (script here).
The second thing I needed to do was examine what metadata was in the JPEG and reduct some of it. I used `exifprobe` and `exiftool -v` to examine the metadata. I ended up using this command on each image:
exiftool -overwrite_original -scanForXMP \ -MakerNotes:SerialNumber='0' -MakerNotes:OwnerName='' -MakerNotes:InternalSerialNumber="0" -XMP:SerialNumber= \ -XMP:OwnerName="Andrew Harvey <andrew.harvey4@gmail.com>" \ -XMP-cc:AttributionName='Andrew Harvey' -XMP-cc:License='http://creativecommons.org/licenses/by/3.0/' -XMP-cc:attributionURL="http://www.flickr.com/photos/andrewharvey4/"\ "file_name.jpg"
http://www.sno.phy.queensu.ca/~phil/exiftool/TagNames/Canon.html was a good reference to find out about the MakerNotes tags. Also it took me a little experimenting and research before finding out that “MakerNotes tags may be edited, but not created or deleted individually.” This is why the SerialNumber tag is set to zero, and not removed. I tried to remove the camera serial numbers, but who knows, Canon probably secretly embed the serial number into the image pixel values as well…
http://wiki.creativecommons.org/XMP also provided me with some hints on how best to embed these JPEGs with at least some form of machine readable tagging as CC BY licensed.
A Great Gnome Panel Applet + A UPnP Enabled Router
I have just discovered that my ADSL router supports UPnP, and that this provides an interface to access 3 important bits of information from the router (external IP address, total bytes sent and total bytes received). I had previously been scraping the router’s web interface to grab the external IP. As for the bytes sent and received, I didn’t even know the router had a method of reporting these.
My first instinct was to look for a Perl library for UPnP, I found two. One in the Ubuntu repositories (and in CPAN) http://search.cpan.org/perldoc?Net::UPnP::GW::Gateway and another which appears to be in neither, http://perlupnp.sourceforge.net/.
I tried out the first one and after some fiddling get it working (though I haven’t yet been able to eliminate the 2 seconds it spends blocked, ie. not executing on the CPU but still not complete).
Next I found a great program that allows you to place an arbitrary command’s output in the Gnome Panel, http://code.google.com/p/compa/. Which resulted in,

The Perl script I use to provide the output to the Compa applet is at http://github.com/andrewharvey/perlmisc/blob/master/upnp_router_inoutbytes_to_compa.pl
The URL shown in Firefox’s status bar isn’t always where you end up.
Unless you are aware of the more technical details of web browsing its reasonable for the average web user to assume that if you hover your mouse over a link and Firefox tells you in the status bar that the link is to http://foobar.com/, then clicking on the link will actually take you to http://foorbar.com/. But sadly this is not the case for out of the box Firefox.
Take a look at a Google search results pages. Hovering your mouse over the links gives one URL in the status bar, yet clicking the link actually takes you somewhere else.
Here is a sample of the HTML for the link,
<a href="http://www.example.com/page1.html" onmousedown="return rwt(this,'','','res','1','$ID1','&sig2=$ID2','$ID3')">Page Title</a>
Hovering over the link, you see in the status bar http://www.example.com/page1.html, but as soon as you mousedown javascript goes ahead and changes the href to something else (keep in mind that Firefox only goes to the new link on mouserelease), so that when you release the mouse your browser takes you to the replacement URL.
The problem I see with this is what if some unsuspecting user checks the link in the status bar, clicks the link thinking they are going one place then get taken somewhere else. This becomes even more of a problem if that site is susceptible to certain kinds of XSS attacks. So you can think your going to https://paypal.com/, and the URL bar after clicking the link goes to https://paypal.com/ but yet you’ve actually got some malicious js or html injected in the paypal.com/ page that you have loaded in your browser window.
I originally thought this was clickjacking, but the Wikipedia article describes that as when a transparent layer on top of the page provides the concealed URL.
Australian States Map/Graph API
I’ve managed to do a couple things all in one here. I’ve made use of some Geoscience Australia Creative Commons licensed material, in a nice little program with a web API, and I’ve aggregated some data from the myschool scraper and parser. Putting them all together gives some nice images like this.
The program for generating these images basically takes an SVG template file with placeholder markers and then fills these values based on the CGI parameters. The API is fairly simple so one should be able to work out how to use it from the example in the README file. Here are the files I used to make the graphs (and the svg versions as WordPress.com won’t let me upload them to here).
ps. This gets cut off when viewing it from the default web interface of this blog, use print preview or even better look at the RSS feed to see the cut off parts. Also I tried to ensure the accuracy of the data, but I cannot be 100% sure that there are no bugs, in fact there are discrepancies with the averages I get from my scrape of myschool and the averages provided in the report on the NPLAN website. The numbers I get seem to be consistent (ie. the state rankings seem mostly the same), but nonetheless not exactly the same as those reported in the report. Although I would be very surprised if all the numbers I got were exactly the same as in the report. I mainly did this to use map/graph code I wrote, so if you really care about how certain state averages compare in these tests look at the reports on the NPLAN website.
The lighter the colour the higher the number.
Primary
| 2008 | 2009 | |
| Literacy |  |
 |
| Numeracy |  |
 |
| All |  |
 |
Secondary
| 2008 | 2009 | |
| Literacy |  |
 |
| Numeracy |  |
 |
| All |  |
 |
anonymous FTP
So I’ve started reading a book about networks, and to complement this I’ve been taking a closer look at my network traffic in Wireshark (really great tool, by the way.).
So I pick an ftp site that I know, ftp://download.nvidia.com/ and see what happens in Wireshark when I visit it in Firefox. At the FTP application level this is what happens,
ftpsite to me: 220 spftp/1.0.0000 Server [69.31.121.43]\r\n
me to ftpsite: USER anonymous\r\n
ftpsite to me: 331 Password required for USER.\r\n
me to ftpsite: PASS mozilla@example.com\r\n
ftpsite to me: 230- \r\n
230- ---------------------------------------------------------------------------\r\n
230- WARNING: This is a restricted access system. If you do not have explicit\r\n
230- permission to access this system, please disconnect immediately!\r\n
230 ----------------------------------------------------------------------------\r\n
But Firefox does not disconnect. So I did some more research and I found no references to “anonymous” users in either RFC 959 (FTP) or RFC 3659 (extensions to FTP). (Though there are references in latter RFCs, see RFC 2228).
The thing I find disconcerting is that I don’t think I have “explicit permission” to access this system. I (or rather Firefox) just guessed a username and password and they happened to let me in (what if I guessed a different username and password that wasn’t anonymous and it let me in?). If the RFC specified that a user of anonymous requires no password, or any password, then I would assume that the FTP server is granting me permission, but I assume rather people just started using anonymous as the user and it caught on…
The real problem here is that there are laws which govern such areas, and it doesn’t help that that I don’t understand what PART 6 – COMPUTER OFFENCES of the CRIMES ACT 1900 (NSW) is saying.
To fix broken audio, unplug faulty USB device.
How weird is this, just recently when I started up my computer lots of stuff was broken, no audio (and /proc/asound/cards was empty, normally it has “0 [Intel ]: HDA-Intel – HDA Intel\nHDA Intel at 0xfa100000 irq 22”), libsensors weren’t reporting any values (eg. no CPU temp reported), eth0 dissapeared from NetworkManager, and probably a host of other things that I didn’t notice. Restarting didn’t fix it.
Well long story short, it turns out that everything magically fixed when I unplugged a USB hard drive that was plugged in. I had seen a lot of concerning messages sent to /var/log/messages from the kernel about it,
Jan 19 09:45:00 host kernel: [ 564.100026] usb 1-3: reset high speed USB device using ehci_hcd and address 2
Jan 19 09:45:00 host kernel: [ 564.237716] sd 8:0:0:0: [sdd] Unhandled error code
Jan 19 09:45:00 host kernel: [ 564.237719] sd 8:0:0:0: [sdd] Result: hostbyte=DID_ABORT driverbyte=DRIVER_OK
that repeated every so often, but I never thought that a dodgy USB device would break the kernel from doing some of its job.
An Idea for a Media-Centreish Interface for a UNIX terminal/shell
Back in July or August this year when I was going through the notes on unix shells for COMP2041 I came up with idea of doing a shell/terminal interface that looked like an interface for a media centre ie. rather than looking like this,
 it would look “like” this (obvious not exactly the same but similar feel),
it would look “like” this (obvious not exactly the same but similar feel),

XBMC skin MediaStream by Team Razorfish. http://xbmc.org/wordpress/wp-content/gallery/mediastream/viewoptions.jpg
The key principles I had in mind were,
- nice aesthetics
- interface similar to a game or media centre
- features easily discoverable for new users
My original motives were that I was just learning all these core-utils commands (ls, cat, mkdir, cp, mv…) and I found that although the shell had tab completion and apropos, it didn’t categorise these or give them in a list of common commands. Then I came up with more abstract ideas,
- categorise common commands and give help on them. eg. File System: ls, cd, cd .., mkdir. Filters: cat, wc, grep…
- parse commands and their argument list based on common styles (eg. GNU style, short -las and long -l –all –size) and provide contextual information (eg hovering over an –argument gives a one line message about what that argument does (perhaps parse the man file to get this info)) also auto-layout the command line as per the argument style.
- it could also parse the pipe lines and display these much more visually so its easier to see what’s piping into what and allow the user to easily change the order/flow of the pipeline.
- process management. don’t force the user to remember Ctrl+C and Ctrl+Z and bg and fg commands, show these as pause and stop icons.
- redirection of output should be easily changed in the interface rather than just adding a < or > to the command line (and allow one to redirect STDOUT to a file AFTER the command has already run (because currently you would need to run the command again, or copy and paste and put up the with new lines that gnome-terminal puts in))
- bookmarking commands (including argmunts) so that those common ones you use that you haven’t remembered yet are quick and easy to use.
- colour STDERR in red.
I haven’t really thought about it on a technical level, but it may not be so portable as say gnome-terminal. I don’t know the really differences among different shells out there so I don’t know how dependent this is on bash or even if it ties bash and the terminal together, but from a beginner user perspective I don’t care about this.
The cloudy idea I have in my mind is basically a GUI/CLI hybrid but I think such a program would need to be careful not to go too far, because it could be made so that after doing an ls -la you could click on a file in the list and rename it, but then we are turning into a file manager in list mode (like Dolphin or Nautilus) which is unnecessary as those tools already exist.
I’m aiming to do come up with a list and more detailed list of requirements and a set of activity and use case scenarios, along with some wire-frame prototypes for such an interface soon. But for now I just needed to get it all out of my head an onto paper (and also public (in case someone tries to patent a concept)).
The Features of My Utopian Music Player
Ideally I would like to write my own music player because I don’t really like any that are currently available (Amarok 1.4, Amarok 2, Songbird, Rhythmbox, Banshee, Exaile). I like features from each but none seem to fit all my needs. All the time I keep rethinking what I should do and I still cannot decide. Anyway this is what my ideal music player would be like…
- Backend Database
- The backend metadata would be stored in an external Postgresql database, with the option for using sqlite for people who don’t want to set up and run postgresql.
- The schema should be good and documented, so that a user can read and write into the database. If not at least give an interface to allow this.
- Full playback information. I want my music player to store the timestamps of every time a given song has been played. I want history too, for instance the times of when the song rating was changed.
- Collection Manger
- I want the music player to be the library not just the librarian. I want to give it a file (say an MP3), along with details such as song title, artist, etc. and I want it to take that file and store it on the hard disk in a nice file structure (like iTunes does). Amarok 1.4 attempts to do this but its really hard, because initially it will just add the file to your playlist and not move it across to your collection, and even then if you change the details say the artist it will not correct this in the folder structure used to store that file.
- Tagging songs. Amarok does this well.
- Web scraper
- Album art and lyric scraping (but who knows you might get sent to jail for writing a scraper for a specific site which you do not know if they have permission to distribute those certain copyrighted lyrics/album art which were available at the time of writing the scraper). Amarok seems to do this well.
- Acoustic Analysis
- Surely there are algorithms to guess the BPM (beats per minute) of a song. I want that integrated into the music player.
- I need a moodbar so I can navigate a song, and to gather contextual information on how the style of the music varies over the song.
- I don’t know much about acoustics, but there must be other algorithm which give meaningful measures of audio. These should be used to group songs and find similar ones.
- This must be done locally, I don’t want to send things to web services (MusicBrainz, http://echonest.com/).
- Navigation
- I want a concept of a “Library” rather than a Playlist. Amarok only has playlists, but 99.9% of the time I want a list of all my songs.
- Statistics
- I want reports. Reports on my listening trends and song collection. eg. http://lastgraph3.aeracode.org/
Now for the solution. I could try everything from writing my own music player from scratch that implements that all (but I gave up on that after I could not decide what programming language to use C, C++, Java, Perl, Python, what GUI widget toolkit to use Qt, GTK+, wxWidgets, graphics api for nice graphs Cairo, raw OpenGL, OpenGL behind Clutter, R’s graph drawing, Processing, or some other CPAN Perl module for drawing nice graphs. I can mix a few but the core app needs one programming language and it needs a core GUI toolkit for the GUI. There is too much choice and I don’t have enough experience to know before hand what is best and what I will find easiest and simplest to use.)
I could try to capture playback statistics by looping last.fm and audioscrobber.com to localhost and capturing the data that Amarok sends. Or I could just write a script for Amarok which captures playback, but this only solves part of the problem and then I’m stuck using a certain application. Alternatively I could just take an existing program and fork it to suit my needs.
There should be more to come on this as I start experimenting.
A Perl Script to Pause/Resume Amarok 1.4 Playback on Screensaver/Screenlock
I’ve just uploaded to GitHub a script to pause Amarok 1.4 playback when the screensaver/screenlock starts and up pause again when closed/unlocked. It addresses the issue I was having with the script at http://nxsy.org/getting-amarok-to-pause-when-the-screen-locks-using-python-of-course where the script would start Amarok if it was not running and it would restart playback on screensaver end/unlock regardless of whether it was playing when the screensaver started.
You could start the script on start-up or plug it into Amarok’s script engine to only be active when Amarok is active.
(Oh and in the future I’ll try to avoid posts that just duplicate item’s from other RSS/Atom feeds that don’t add much extra value.)
Computer Graphics Notes
Not really complete…
Colour notes here, transformations notes here.
Parametric Curves and Surfaces
Parametric Representation
eg.

Continuity
Parametric Continuity
- If the first derivative of a curve is continuous, we say it has C1 continuity.
Geometric Continuity
- If the magnitude of the first derivative of a curve changes but the direction doesn’t then, we say it has G1 continuity.
- Curves need G2 continuity in order for a car to drive along them. (ie. not instantly change steering wheel angle at any points).
Control Points
Control points allow us to shape/define curves visually. A curve will either interpolate or approximate control points.
Natural Cubic Splines

- Interpolate control points.
- A cubic curve between each pair of control points
- Four unknowns,
-
- interpolating the two control points gives two,
- requiring that derivatives match at end of points of these curves gives the other two.
-
- Moving one control point changes the whole curve (ie. no local control over the shape of the curve)
Bezier Curve

This Bezier curve shown has two segments, where each segment is defined by 4 control points. The curve interpolates two points and approximates the other two. The curve is defined by a Bernstein polynomial. In the diagram changing points 1 and 2 only affects that segment. Changing the corner points (0 and 3) each only affect the two segments that they boarder.
Some properties of Bezier Curves:
- Tangent Property. Tangent at point 0 is line 0 to 1, similarly for point 3.
- Convex Hull Property. The curve lies inside the convex hull of the control points. (The corollary of this is if the control points are colinear, the curve is a line.)
- They have affine invariance.
- Can’t fluctuate more than their control polygon does.
- Bezier’s are a special case of B-spline curves.

We can join two Bezier curves together to have C1 continuity (where B1(P0, P1, P2, P3) and B2(P0, P1, P2, P3)) if P3 – P2 = P4 – P3. That is P2, P3, and P4 are colinear and P3 is the midpoint of P2 and P4. To get G1 continuity we just need P2, P3, and P4 to be colinear. If we have G1 continuity but not C1 continuity the curve still won’t have any corners but you will notice a “corner” if your using the curve for something else such as some cases in animation. [Also if the curve defined a road without G1 continuity there would be points where you must change the steering wheel from one rotation to another instantly in order to stay on the path.]
De Casteljau Algorithm
De Casteljau Algorithm is a recursive method to evaluate points on a Bezier curve.

To calculate the point halfway on the curve, that is t = 0.5 using De Casteljau’s algorithm we (as shown above) find the midpoints on each of the lines shown in green, then join the midpoints of the lines shown in red, then the midpoint of the resulting line is a point on the curve. To find the points for different values of t, just use that ratio to split the lines instead of using the midpoints. Also note that we have actually split the Bezier curve into two. The first defined by P0, P01, P012, P0123 and the second by P0123, P123, P23, P3.
Curvature
The curvature of a circle is 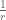
The curvature of a curve at any point is the curvature of the osculating circle at that point. The osculating circle for a point on a curve is the circle that “just touches” the curve at that point. The curvature of a curve corresponds to the position of the steering wheel of a car going around that curve.
Uniform B Splines
Join with C2 continuity.
Any of the B splines don’t interpolate any points, just approximate the control points.
Non-Uniform B Splines
Only invariant under affine transformations, not projective transformations.
Rational B Splines
Rational means that they are invariant under projective and affine transformations.
NURBS
Non-Uniform Rational B Splines
Can be used to model any of the conic sections (circle, ellipse, hyperbola)
=====================
3D
When rotating about an axis in OpenGL you can use the right hand rule to determine the + direction (thumb points in axis, finger indicate + rotation direction).
We can think of transformations as changing the coordinate system, where (u, v, n) is the new basis and O is the origin.

This kind of transformation in is known as a local to world transform. This is useful for defining objects which are made up of many smaller objects. It also means to transform the object we just have to change the local to world transform instead of changing the coordinates of each individual vertex. A series of local to world transformations on objects builds up a scene graph, useful for drawing a scene with many distinct models.
Matrix Stacks
OpenGL has MODELVIEW, PROJECTION, VIEWPORT, and TEXTURE matrix modes.
- glLoadIdentity() – puts the Identity matrix on the top of the stack
- glPushMatrix() – copies the top of the matrix stack and puts it on top
- glPopMatrix()
For MODELVIEW operations include glTranslate, glScaled, glRotated… These are post multiplied to the top of the stack, so the last call is done first (ie. a glTranslate then glScaled will scale then translate.).
Any glVertex() called have the value transformed by matrix on the top of the MODELVIEW stack.
Usually the hardware only supports projection and viewport stacks of size 2, whereas the modelview stack should have at least a size of 32.
The View Volume
Can set the view volume using,(after setting the the current matrix stack to the PROJECTION stack
- glOrtho(left, right, bottom, top, near, far)

(Source: Unknown) - glFrustum(left, right, bottom, top, near, far)

(Source: Unknown) - gluPerspective(fovy, aspect, zNear, zFar)

(Source: Unknown)



In OpenGL the projection method just determines how to squish the 3D space into the canonical view volume.
Then you can set the direction using gluLookAt (after calling one of the above) where you set the eye location, a forward look at vector and an up vector.
When using perspective the view volume will be a frustum, but this is more complicated to clip against than a cube. So we convert the view volume into the canonical view volume which is just a transformation to make the view volume a cube at 0,0,0 of width 2. Yes this introduces distortion but this will be compensated by the final window to viewport transformation.
Remember we can set the viewport with glViewport(left, bottom, width, height) where x and y are a location in the screen (I think this means window, but also this stuff is probably older that modern window management so I’m not worrying about the details here.)
Visible Surface Determination (Hidden Surface Removal)
First clip to the view volume then do back face culling.
Could just sort the polygons and draw the ones further away first (painter’s algorithm/depth sorting). But this fails for those three overlapping triangles.
Can fix by splitting the polygons.
BSP (Binary Space Partitioning)
For each polygon there is a region in front and a region behind the polygon. Keep subdividing the space for all the polygons.
Can then use this BSP tree to draw.
void drawBSP(BSPTree m, Point myPos{
if (m.poly.inFront(myPos)) {
drawBSP(m.behind, myPos);
draw(m.poly);
drawBSP(m.front, myPos);
}else{
drawBSP(m.front, myPos);
draw(m.poly);
drawBSP(m.behind, myPos);
}
}
If one polygon’s plane cuts another polygon, need to split the polygon.
You get different tree structures depending on the order you select the polygons. This does not matter, but some orders will give a more efficient result.
Building the BSP tree is slow, but it does not need to be recalculated when the viewer moves around. We would need to recalculate the tree if the polygons move or new ones are added.
BSP trees are not so common anymore, instead the Z buffer is used.
Z Buffer
Before we fill in a pixel into the framebuffer, we check the z buffer and only fill that pixel is the z value (can be a pseudo-depth) is less (large values for further away) than the one in the z buffer. If we fill then we must also update the z buffer value for that pixel.
Try to use the full range of values for each pixel element in the z buffer.
To use in OpenGL just do gl.glEnable(GL.GL_DEPTH_TEST) and to clear the z-buffer use gl.glClear(GL.GL_DEPTH_BUFFER_BIT).
Fractals
L-Systems
Line systems. eg. koch curve
Self-similarity
- Exact (eg. sierpinski trangle)
- Stochastic (eg. mandelbrot set)
IFS – Iterated Function System
================================================
Shading Models
There are two main types of rendering that we cover,
- polygon rendering
- ray tracing
Polygon rendering is used to apply illumination models to polygons, whereas ray tracing applies to arbitrary geometrical objects. Ray tracing is more accurate, whereas polygon rendering does a lot of fudging to get things to look real, but polygon rendering is much faster than ray tracing.
- With polygon rendering we must approximate NURBS into polygons, with ray tracing we don’t need to, hence we can get perfectly smooth surfaces.
- Much of the light that illuminates a scene is indirect light (meaning it has not come directly from the light source). In polygon rendering we fudge this using ambient light. Global illumination models (such as ray tracing, radiosity) deal with this indirect light.
- When rendering we assume that objects have material properties which we denote k(property).
- We are trying to determine I which is the colour to draw on the screen.
We start with a simple model and build up,
Lets assume each object has a defined colour. Hence our illumination model is 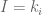
Now we add ambient light into the scene. Ambient Light is indirect light (ie. did not come straight from the light source) but rather it has reflected off other objects (from diffuse reflection). 
Next we use the diffuse illumination model to add shading based on light sources. This works well for non-reflective surfaces (matte, not shiny) as we assume that light reflected off the object is equally reflected in every direction.
Lambert’s Law
“intensity of light reflected from a surface is proportional to the cosine of the angle between L (vector to light source) and N(normal at the point).”
Gouraud Shading
Use normals at each vertex to calculate the colour of that vertex (if we don’t have them, we can calculate them from the polygon normals for each face). Do for each vertex in the polygon and interpolate the colour to fill the polygon. The vertex normals address the common issue that our polygon surface is just an approximation of a curved surface.
To use gouraud shading in OpenGL use glShadeModel(GL_SMOOTH). But we also need to define the vertex normals with glNormal3f() (which will be set to any glVertex that you specify after calling glNormal).
Highlights don’t look realistic as you are only sampling at every vertex.
Interpolated shading is the same, but we use the polygon normal as the normal for each vertex, rather than the vertex normal.
Phong Shading
Like gouraud, but you interpolate the normals and then apply the illumination equation for each pixel.
This gives much nicer highlights without needing to increase the number of polygons, as you are sampling at every pixel.
Phong Illumination Model
Diffuse reflection and specular reflection.

- Components of the Phong Model (Brad Smith, http://commons.wikimedia.org/wiki/File:Phong_components_version_4.png)


(Source: COMP3421, Lecture Slides.)

n is the Phong exponent and determines how shiny the material (the larger n the smaller the highlight circle).
Flat shading. Can do smooth shading with some interpolation.
If you don’t have vertex normals, you can interpolate it using the face normals of the surrounding faces.
Gouraud interpolates the colour, phong interpolates the normals.
Attenuation
inverse square is physically correct, but looks wrong because real lights are not single points as we usually use in describing a scene, and
For now I assume that all polygons are triangles. We can store the normal per polygon. This will reneder this polygon, but most of the time the polygon model is just an approximation of some smooth surface, so what we really want to do is use vertex normals and interpolate them for the polygon.
Ray Tracing
For each pixel on the screen shoot out a ray and bounce it around the scene. The same as shooting rays from the light sources, but only very few would make it into the camera so its not very efficient.
Each object in the scene must provide an intersection(Line2D) function and a normal (Point3D) function
Ray Tree
Nodes are intersections of a light ray with an object. Can branch intersections for reflected/refracted rays. The primary ray is the original ray and the others are secondary rays.
Shadows
Can do them using ray tracing, or can use shadow maps along with the Z buffer. The key to shadow maps is to render the scene from the light’s perspective and save the depths in the Z buffer. Then can compare this Z value to the transformed Z value of a candidate pixel.
==============
Rasterisation
Line Drawing
DDA
- You iterate over x or y, and calculate the other coordinate using the line equation (and rounding it).
- If the gradient of the line is > 1 we must iterate over y otherwise iterate over x. Otherwise we would have gaps in the line.
- Also need to check if x1 is > or < x2 or equal and have different cases for these.
Bresenham
- Only uses integer calcs and no multiplications so its much faster than DDA.
- We define an algorithm for the 1st octant and deal with the other octant’s with cases.
- We start with the first pixel being the lower left end point. From there there are only two possible pixels that we would need to fill. The one to the right or the one to the top right. Bresenham’s algorithm gives a rule for which pixel to go to. We only need to do this incrementally so we can just keep working out which pixel to go to next.
- The idea is we accumulate an error and when that exceeds a certain amount we go up right, then clear the error, other wise we add to the error and go right.
We use Bresenham’s algorithm for drawing lines this is just doing linear interpolation, so we can use Bresenham’s algorithm for other tasks that need linear interpolation.
Polygon Filling
Scan line Algorithm
The Active Edge List (AEL) is initially empty and the Inactive Edge List (IEL) initially contains all the edges. As the scanline crosses an edge it is moved from the IEL to the AEL, then after the scanline no longer crosses that edge it is removed from the AEL.
To fill the scanline,
- On the left edge, round up to the nearest integer, with round(n) = n if n is an integer.
- On the right edge, round down to the nearest integer, but with round(n) = n-1 if n is an integer.
Its really easy to fill a triangle, so an alternative is to split the polygon into triangles and just fill the triangles.
===============
Anti-Aliasing
Ideally a pixel’s colour should be the area of the polygon that falls inside that pixel (and is on top of other polygons on that pixel) times the average colour of the polygon in that pixel region then multiply with any other resulting pixel colours that you get from other polygons in that pixel that’s not on top of any other polygon on that pixel.
Aliasing Problems
- Small objects that fall between the centre of two adjacent pixels are missed by aliasing. Anti-aliasing would fix this by shading the pixels a gray rather than full black if the polygon filled the whole pixel.
- Edges look rough (“the jaggies”).
- Textures disintegrate in the distance
- Other non-graphics problems.
Anti-Aliasing
In order to really understand this anti-aliasing stuff I think you need some basic understanding of how a standard scene is drawn. When using a polygon rendering method (such as is done with most real time 3D), you have a framebuffer which is just an area of memory that stores the RGB values of each pixel. Initially this framebuffer is filled with the background colour, then polygons are drawn on top. If your rending engine uses some kind of hidden surface removal it will ensure that the things that should be on top are actually drawn on top.
Using the example shown (idea from http://cgi.cse.unsw.edu.au/~cs3421/wordpress/2009/09/24/week-10-tutorial/#more-60), and using the rule that if a sample falls exactly on the edge of two polygons, we take the pixel is only filled if it is a top edge of the polygon.

- Anti-Aliasing Example Case. The pixel is the thick square, and the blue dots are samples.
No Anti-Aliasing
With no anti-aliasing we just draw the pixel as the colour of the polygon that takes up the most area in the pixel.
Pre-Filtering
- We only know what colours came before this pixel, and we don’t know if anything will be drawn on top.
- We take a weighted (based on the ratio of how much of the pixel the polygon covers) averages along the way. For example if the pixel was filled with half green, then another half red, the final anti-aliased colour of that pixel would determined by,
Green (0, 1, 0) averaged with red (1, 0, 0) which is (0.5, 0.5, 0). If we had any more colours we would then average (0.5, 0.5, 0) with the next one, and so on. - Remember weighted averages,
where you are averagingand
with weights
and
respectively.
- Pre-filtering is designed to work with polygon rendering because you need to know the ratio which by nature a tracer doesn’t know (because it just takes samples), nor does it know which polygons fall in a given pixel (again because ray tracers just take samples).
- Pre-filtering works very well for anti-aliasing lines, and other vector graphics.
Post-Filtering
- Post-filtering uses supersampling.
- We take some samples (can jitter (stochastic sampling) them, but this only really helps when you have vertical or horizontal lines moving vertically or horizontally across a pixel, eg. with vector graphics)
of the samples are Green, and
are red. So we use this to take an average to get the final pixel colour of
- We can weight these samples (usually centre sample has more weight). The method we use for deciding the weights is called the filter. (equal weights is called the box filter)
- Because we have to store all the colour values for the pixel we use more memory than with pre-filtering (but don’t need to calculate the area ratio).
- Works for either polygon rendering or ray tracing.

Can use adaptive supersampling. If it looks like a region is just one colour, don’t bother supersampling that region.
OpenGL
Often the graphics card will take over and do supersamling for you (full scene anti aliasing).
To get OpenGL to anti-alias lines you need to first tell it to calculate alpha for each pixel (ie. the ratio of non-filled to filled area of the pixel) using, glEnable(GL_LINE_SMOOTH) and then enable alpha blending to apply this when drawing using,
glEnable(GL_BLEND); glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
You can do post-filtering using the accumulation buffer (which is like the framebuffer but will apply averages of the pixels), and jittering the camera for a few times using accPerspective.
Anti-Aliasing Textures
A texel is a texture pixel whereas a pixel in this context refers to a pixel in the final rendered image.
When magnifying the image can use bilinear filtering (linear interpolation) to fill the gaps.
Mip Mapping
Storing scaled down images and choose closes and also interpolate between levels where needed. Called trilinear filtering.
Rip Mapping helps with non uniform scaling of textures. Anisotropic filtering is more general and deals with any non-linear transformation applied to the texture
Double Buffering
We can animate graphics by simply changing the framebuffer, however if we start changing the framebuffer and we cannot change it faster than the rate the screen will display the contents of the frame buffer, it gets drawn when we have only changed part of the framebuffer. To prevent this, we render the image to an off screen buffer and when we finish we tell the hardware to switch buffers.
Can do on-demand rendering (only refill framebuffer when need to) or continuois rendeing (draw method is called at a fixed rate and the image is redrawn regardless of whether the image needs to be updated.)
LOD
Mip Mapping for models. Can have some low poly models that we use when far away, and use the high res ones when close up.
Animation
Key-frames and tween between them to fill up the frames.
===============
Shaders
OpenGL 2.0 using GLSL will let us implement out own programs for parts of the graphics pipeline particularly the vertex transformation stage and fragment texturing and colouring stage.
Fragments are like pixels except they may not appear on the screen if they are discarded by the Z-buffer.
Vertex Shaders
- position tranformation and projection (set gl_Position), and
- lighting calculation (set gl_FrontColor)
Fragment Shaders
- interpolate vertex colours for each fragment
- apply textures
- etc.
set gl_FragColor.
 Google Reader Shared Items
Google Reader Shared Items
- An error has occurred; the feed is probably down. Try again later.
License

The content on this blog by Andrew Harvey, unless otherwise noted is licensed under a Creative Commons Attribution-Share Alike 3.0 Australia License.

{kind=link}
{kind=link}