Archive
Operating Systems Notes
Here are are some rough notes I put together as part of revision for a uni course. They are heavily based on the course lecture notes by Kevin Elphinstone and Leonid Ryzhyk. All diagrams are sourced from those lecture notes, some of which are in turn from the text book, A. Tannenbaum, Modern Operating Systems.
OS Overview
- The OS hides the details of the hardware and provides an abstraction for user code.
- The OS is responsible for allocating resources (cpu, disk, memory…) to users and processes. It must ensure no starvation, progress, and that the allocation is efficient.
- The kernel is the portion of the OS running in privileged mode (hardware must have some support for privileged mode for the OS to be able to enforce the user and kernel mode distinction).

- When the hardware is in privileged mode all instructions and registers are available. When the hardware is in user mode only a limited sets of instructions, registers and memory locations are available. For instance when in user mode, it is not possible to disable interrupts because otherwise a user could ensure that the OS never gets control again..
- A process is a instance of a program in execution.
- A process in memory usually has at least three segments. The text segment for the program code (instructions), a data segment called the heap for global variables and dynamically allocated memory, and a stack segment used for function calls.
- A process also has an execution context which includes registers in use, program counter, stack pointer, etc.
- In a Monolithic OS different parts of the OS like processor allocation, memory management, devices and file systems are not strictly separated into separate layers but rather intertwined, although usually some degree of grouping and separation of components is achieved.

System Calls
- The system call interface represents the abstract machine provided by the operating system.
- man syscalls
- Syscall numbers
- hardware syscall instruction
Processes and Threads
- Processes can contain one or more threads. These threads are units of execution, and always belong to a process.
- A process can terminate by,
- normal exit (voluntary), usually returning EXIT_SUCCESS
- error exit (voluntary), usually returning EXIT_FAILURE
- fatal error (involuntary), eg. segfault, divide by zero error
- killed by another process (involuntary), eg. pkill (sending the SIGTERM signal)
- Thread states

- Running to ready could be from a voluntary yield, or end of time allocated by the CPU, so the scheduler moves the thread to the Ready queue to give another process a go.
- Running to blocked could be from a calling a syscall and waiting for the response, waiting on a device, waiting for a timer, waiting for some resource to become available, etc.
- The scheduler (also called the dispatcher) decides which thread to pick from the read queue to run.

- The idea is that a process with multiple threads can still make process when a single thread blocks, as if one thread blocks, the others can still be working. In more recent times, it allows a process to have threads running on multiple CPU’s on modern multi-core machines.
- The other model is finite-state machine where syscall’s don’t block but instead allow the program to continue running and then send the process an interrupt when the syscall has been dealt with. This is not as easy to program though.


During the system initialisation background processes (called daemon’s on linux, service’s on windows) and foreground processes can be started.
Threads Implementation
- Kernel-threads vs. User-level threads.
- User-level threads

- Thread management is handled by the process (usually in a runtime support library)
- The advantages are,
- switching threads at user-level is much cheaper than the OS doing a context switch
- you can tune your user-level thread scheduler, and not just use the OS provided one
- no OS support for threads needed
- The disadvantages are,
- your threads must yield(), you can’t really on an interrupt to give your scheduler control again (this is known as co-operative multithreading)
- cannot take advantage of multiple CPU’s
- if one of your user-level threads gets blocks by the OS, your whole process gets blocked (because the OS only sees one thread running)
- Kernel-level Threads

- Thread management is done by the kernel through system calls
- The downside is thread management (creation, destruction, blocking and unblocking threads) requires kernel entry and exit, which is expensive
- The upside is we now have preemptive multithreading (the OS just takes control when it wants to schedule another process, so no need to rely on the thread to yield), can take advantage of a multiprocessor, and individual threads can have isolated blocking.
- A Thread switch can happen in between execution of any two instructions, at the same time it must be transparent to the threads involved in the switch. So the OS must save the state of the thread such as the program counter (instruction pointer), registers, etc. as the thread context. The switch between threads by the OS is called a context switch.


Concurrency
- A race condition occurs when the computation depends on the relative speed of two or more processes.
- Dealing with race conditions,
- Mutual exclusion
- Identify the shared variables,
- identify the code sections which access these variables (critical region)
- and use some kind of mutual exclusion (such as a lock) to ensure that at most only one process can enter a critical region at a time.
- Lock-free data structures
- Allow the concurrent access to shared variables, but design data structures to be designed for concurrent access
- Message-based communication
- Eliminate shared variables and instead use communication and synchronisation between processes.
- Mutual exclusion
- Mutual Exclusion – enter_region() and leave_region().

- Hardware usually provides some mutual exclusion support by providing an atomic test and set instruction.
- A uniprocessor system runs one thread at a time, so concurrency arises from preemptive scheduling. But with multiprocessor machines concurrency also arises from running code in parallel using shared memory.
- The problem with the approach to mutual exclusion so far is that when process B is blocked, it just sits in a loop waiting for the critical region to become available. Can fix this by using sleep and wakeup. We use a mutex lock for this.
- Blocking locks can only be implemented in the kernel, but can be accessed by user-level processes by system calls.
- A mutex allows at most one process to use a resource, a semaphore allows at most N processes.
- Producer-consumer problem
- Producer can sleep when buffer is full, and wake up when space available.
- Consumer can sleep when buffer is empty and wake up when some items available.
- Can do using semaphores or condition variables.
- Monitors are set up to only allow one process/thread to operate inside it at once, with extra requests put in a queue. Implemented by the compiler.
- Condition variables. cv_create, cv_destroy, cv_wait, cv_signal, cv_broadcast
- Dining philosophers problem. Need to prevent deadlock.

Deadlock
- A set of processes is deadlocked if each process in the set is waiting for an event that only another process in the set can cause.
- Four conditions for deadlock:
- Mutual exclusion condition (device not shareable amongst threads)
- Hold and wait condition (a resource can be held, but then block awaiting more resources)
- Can attack this by requiring all process ask for all resources at the start, and only start if they are granted.
- No preemption condition – previously granted resources cannot be forcibly taken away
- Circular wait condition
- Always request resources in the same order
- Dealing with deadlock:
- ignore the problem
- detect and recover
- dynamic avoidance (careful resource allocation) – we require some information in advance like which resources and how many will be needed before process starts.
- Bankers algorithm
- prevention (negate one of the four conditions for deadlock)
- Starvation is slightly different to deadlock as the system can be making progress, but there are some processes which never make progress.
File Systems
- File systems provide an abstraction of the physical disk. They allow you to store files in a structured manner on a storage device.
- The file system abstraction,

- Architecture of the OS storage stack,

- The application interacts with the system call interface which on linux provides creat, open, read, write, etc.
- In the case of modern hard drives,

- The disk controller (between device driver and physical disk) hides disk geometry and exposes a linear sequence of blocks.
- The device driver hides the device specific protocol to communicate with the disk.
- The disk scheduler takes in requests coming from different processes and schedules them to send one by one to the device driver.
- The buffer cache keeps blocks in memory to improve read and write times for frequently accessed blocks.
- The file system (FS) hides the block numbers and instead exposes the directory hierarchy, files, file permissions, etc. To do this it must know which blocks relate to which file, and which part of the file. It must also manage how to store this on the blocks of the linear address space of the disk, keeping track of which blocks are in use. See Allocation Strategies
- The virtual file system (VFS) provides an interface so that different file systems which are suitable for VFS (ie. they have the concept of files, directories, etc..) can be accessed uniformly.
- The open file table (OF table) and file descriptor table (FD table) keep track of files opened by user-level processes.



There are many popular file systems in use today. FAT16, FAT32 are good for embedded devices; Ext2, Ext3, Ext4 are designed for magnetic disks, ISO9660 is designed for CD-ROM’s, JFFS2 is optimised for flash memory as you don’t want to write to the same location too many times as it wears out. Others include NTFS, ReiserFS, XFS, HFS+, UFS2, ZFS, JFS, OCFS, Btrfs, ExFAT, UBIFS.
Performance issues with standard magnetic disks
- To access a block on a disk the head must move to the required track (seek time), then we have to wait until the required block on the track reaches the head (rotational delay). We also have some mostly fixed overhead for the data to be passed between the device and the driver (transfer time).
- Total average access time,
. Where r is the rotational speed, b is the number of bytes to transfer, N is the number of bytes per track and
is the seek time.
- Seek time is the most expensive, so we want to ensure that our disk arm scheduler gives good performance.
- First-in, First-out (no starvation)
- Shortest seek time first (good performance, but can lead to starvation)
- Elevator (SCAN) (head scans back and forth over the disk. no great starvation, sequential reads are poor in one of the directions)
- Circular SCAN (head scans over the disk in one direction only)
Block Allocation Strategies
- Contiguous Allocation
- Gives good performance for sequential operations as all the blocks for a file are together in order
- though you need to know the maximum file size at creation
- as files are deleted, free space is fragmented (external fragmentation)
- Dynamic Allocation
- Blocks allocated as needed, hence the blocks for a file could be all over the place on the disk
- need to keep track of where all the blocks are and the order for each file
External fragmentation – space wasted external to the allocated regions, this space becomes unusable as its not contiguous (so you have lots of small spaces but you need a larger space to fit a whole file in)
Internal fragmentation – space wasted internal to the allocated memory regions, eg. you get a 4K block allocated and only use 1K, but the OS can’t give the leftover 3K to someone else.
Keeping track of file blocks
- File allocation table (used for FAT16 and FAT32)
- inode based FS; keep an index node for each file which stores all the blocks of the file.

- Directories are stored as normal files but the FS gives these file special meaning.
- A directory file stores a list of directory entries, where each entry containing the file name (because Ext2/3/4 store these with the directory file, not the inode for the file), attributes and the file i-node number.
- Disk blocks (sectors) have a hardware set size, and the file system has a filesystem set block size which is sector size * 2^N, for some N. A larger N means large files need less space for the inode, but smaller blocks waste less space for lots of small files.
- Ext2 inodes

- The top bunch of data is file attributes. Block count is the number of disk blocks the file uses.
- The direct blocks area stores index’s for the first 12 blocks used by the file.
- The single indirect is a block numbers to a block which contains more block numbers.w

System call interface

- At the system call level a file descriptor is used to keep track of open files. The file descriptor is associated with the FS inode, a file pointer of where to read or write next and the mode the file was opened as like read-only.
- Most Unix OS’s maintain a per-process fd table with a global open file table.


VFS
- Provides a single system call interface for many file systems.
- the application can write file access code that doesn’t depend on the low level file system
- device can be hard disk, cd-rom, network drive, an interface to devices (/dev), an interface to kernel data structures (/proc)




Journaling file system keeps a journal (or log) of FS actions which allows for the FS to recover if it was interrupted when performing an action that is not atomic, but needs to be.
Memory Management and Virtual Memory
- The OS needs to keep track of physical memory, what’s in use and which process is it allocated to. It must also provide applications with a view of virtual memory that they are free to use.
- Swapping (sometimes called paging) is where memory is transferred between RAM and disk to allow for more data in memory than we have space for in physical RAM. On base-limit MMU’s swapping only allows who programs memory allocation to be swapped to disk, rather than just pages at a time as with virtual memory, hence you can’t use swapping here to allow programs larger than memory to run.
- If we are only running one program we can give it all of memory (and either run the in part of it, or in some other ROM). However many systems need more than one process to be running at the same time. Multiprogramming also means that we can be utilising the CPU even when a process is waiting on I/O (ie. give the CPU to the other process). But to support multiprogramming we need to divide memory up.
- We could divide memory up into fixed size partitions and allocate these to processes, but this creates internal fragmentation (wasted space inside the partition allocated).
- Using dynamic partitioning we give each process exactly how much it needs, though this assumes we know how much memory we need before the process is started. This approach also leads to external fragmentation where we have lots of little unallocated gaps, but these are too small to be used individually.
- Approaches to dynamic partitioning include first-fit, next-fit, best-fit and worst-fit.
- Binding addresses in programs
- Compile time
- Load time
- Run time
- Protection – we only want each process to be able to access memory assigned to that process, not other process
- Base and Limit Registers – set by the kernel on a context switch, the hardware handles the rest
- Virtual Memory – two variants
- Paging
- Partition physical memory into small equal sized chunks called frames.
- Divide each process’s virtual (logical) address space into same size chunks called pages. So a virtual memory address consists of a page number and an offset within that page.
- OS maintains a page table which stores the frame number for each allocated virtual page.

- No external fragmentation, small internal fragmentation.
- Allows sharing of memory
- Provides a nice abstraction for the programmer
- Implemented with the aid of the MMU (memory management unit).
- Segmentation
- A program’s memory can be divided up into segments (stack, symbol table, main program…)
- Segmentation provides a mapping for each of these segments using a base and limit.

- Paging


Virtual Memory
- If a program attempts to access a memory address which is not mapped (ie. is an invalid page) a page fault is triggered by the MMU which the OS handles.
- Two kinds of page faults,
- Illegal Address (protection error) – signal or kill the process
- Page not resident – get an empty frame or load the page from disk, update the page table, and restart the faulting instruction.
- Each entry in the page table not only has the corresponding frame number but also a collection of bits like protection bits, caching disabled bit, modified bit, etc.
- Page tables are implemented as a data structure in main memory. Most processes don’t use the full 4GB address space so we need a data structure that doesn’t waste space.
- The two level page table is commonly used,

- An alternative is the inverted page table,

- The IPT grows with size of RAM, not virtual address space like the two level page table.
- Unlike two level page table which is required for each process, you only need one IPT for the whole machine. The downside is sharing pages is hard.


- Accessing the page table creates an extra overhead to memory access. A cache for page table entries is used called a translation look-aside buffer (TLB) which contains frequently used page table entries.
- TLB can be hardware or software loaded.
- TLB entries are process specific so we can either flush the TLB on a context switch or give entries an address-space ID so that we can have multiple processes entries in the TLB at the same time.
- Principle of Locality (90/10 rule)
- Temporal Locality is the principle that accesses close together in terms of time are likely to be to the same small set of resources (for instance memory locations).
- Spatial locality is the principle that subsequent memory accesses are going to be close together (in terms of their address) rather than random. array loop example
- The pages or segments required by an application in a time window (
) is called its memory working set.
- Thrashing,

- To recover from thrashing, just suspend some processes until it eases.

- Fetch policy – when should a page be brought into memory? on demand, or pre-fetch?
- Replacement policy – defines which page to evict from physical memory when its full and you start swapping to disk.
- Optimal
- FIFO – problem is that age of a page isn’t necessarily related to its usage
- Least Recently Used – works well but need to timestamp each page when referenced.
- Clock (aka. Second Chance) – an approximation of LRU. Uses a usage or reference bit in the frame table
- Resident Set Size – how many frames should each process have?
- Fixed allocation
- Variable allocation – give enough frames to result in an acceptable fault rate
Input Output
- Programmed I/O (polling or busy waiting)
- Interrupt Driven I/O
- Processor is interrupted when I/O module (controller) is ready to exchange data
- Consumes processor time because every read and write goes through the processor
- Direct Memory Access (DMA)
- Processor sent interrupt at start and end, but is free to work on other things while the device is transferring data directly to memory.

Scheduling
- The scheduler decides which task to run next. This is used in multiple contexts, multi-programmed systems (threads or processes on a ready queue), batch system (deciding which job to run next), multi-user system (which user gets privilege?).
- Application behaviour
- CPU bound – completion time largely determined by received CPU time
- I/O bound – completion time largely determined by I/O request time
- Preemptive (requires timer interrupt, ensures rouge processes can’t monopolise the system) v non-preemptive scheduling.
- Scheduling Algorithms can be categorised into three types of systems,
- Batch systems (no users waiting for the mouse to move)
- Interactive systems (users waiting for results)
- Round Robin – each process is run and if it is still running after some timeslice t, the scheduler preempts it, putting it on the end of the ready queue, and scheduling the process on the head of the ready queue.
If the timeslice is too large the system becomes sluggy and unresponsive, if it is too small too much time is wasted on doing the context switch. - The traditional UNIX scheduler uses a priority-based round robin scheduler to allow I/O bound jobs to be favoured over long-running CPU-bound jobs.
- Round Robin – each process is run and if it is still running after some timeslice t, the scheduler preempts it, putting it on the end of the ready queue, and scheduling the process on the head of the ready queue.
- Realtime systems (jobs have deadlines that must be meet)
- Realtime systems are not necessarily fast, they are predictable.
- To schedule realtime tasks we must know, its arrival time
, maximum execution time (service time), deadline (
).
- tasks could be periodic or sporadic.
- slack time is time when the CPU is not being used, we are waiting for the next task to become available.
- two scheduling algorithms,
- Rate Monotonic – priority driven where priorities are based on the period of each task. ie. the shorter the period the higher the priority
- Earliest Deadline First – guaranteed to work if set of tasks are schedulable. The earlier the deadline the higher the priority.
Multiprocessor Systems
- For this section we look at shared-memory multiprocessors.
- There are uniform memory accesses multiprocessors and non-uniform memory access multiprocessors which access some parts of memory slower than other parts. We focus on the UMA MP’s.
- “Spinlocking on a uniprocessor is useless, as another thread on the same processor needs to release it, so blocking asap is desirable. On a multiprocessor, the thread holding the lock may be presently active on another processor, and it could release the lock at any time.
On a multiprocessor, spin-locking can be worthwhile if the average time spent spinning is less than the average overheads of context switch away from, and back to, the lock requester.” - Thread affinity refers to a thread having some preferred processor to run on an a multiprocessor machine. For instance if thread A started on cpu0 it may want to be scheduled again on cpu0 rather than cpu1 as parts of the cache may still be intact.
- Multiprocessor systems have multiple ready queues, as just one ready queue would be a shared resource which introduces lock contention.
Security
Security Engineering Notes
Here are are some rough notes I put together as part of revision for a uni course.
Security Engineering
- CIA
- Confidentiality
- Integrity
- Availability
- Some other attributes include,
- Authenticity
- Privacy
- Accountability,
- Non-reputability
- Receipt-freeness (for voting systems)
- Methods of attack
- Brute Force
- Deception/Social Engineering
- Calculated attack on a vulnerability
- Insider (both intentional and unintentional/accidental)
- Mitigation techniques: Keeping logs and conducting audits could. Also least privilege to prevent accidental insider attacks.
- Chance (right place at the right time)
- Accidental
- Reliable systems (protect against random failures)
- Secure systems (protect against targeted deliberate attacks)
- Assets which need to be protected
- Tangible (eg. documents)
- Non-tangible (eg. reputation)
- Security Engineering: Protecting assets against threats.
- Kerckhoff’s Principle – “the security of the cryptosystem must not depend on keeping secret the crypto-algorithm. It must depend only on keeping secret the key.”
- Because, its often easier to change the key after a compromise or possible compromise than changing the algorithm,
- and it’s usually also harder to keep the algorithm secret (can be reverse-engineered or bought) compared to the key
Crypto
- Code (hidden meaning, ie. A spy using a phase that seems normal, but actually has some other hidden meaning)
- Plaintext -> E(encryption key) Ciphertext -> D(decryption key)
- Symmetric-key cryptography – Encryption key can be calculated from the decryption key and vice versa (usually they are the same though). The sender and receiver must agree upon the keys first. Two types,
- Stream Ciphers – operate one bit at a time (eg. RC4)
- Block Ciphers – operate on a group of bits at a time (eg. DES and AES/Rijndael)
- Block chaining is used to make each block of cipher text depend on all the previous blocks of plaintext.
- Public-key Cryptography (asymmetric-key) – public and private keys where you cannot (or is really hard to) calculate one from the other. (eg. RSA)
- One problem is that an attacker can use an adaptive chosen plaintext attack, where they encrypt a large number of messages using the target’s public key. A fix is to pad messages with a long random string.
- Can be used to do digital signatures. (encrypt your message M (though in practice a one way hash is used instead) using your private key, verifiers just decrypt using your public key as only someone with the private key (ie. you) could have successfully encrypted M)
- Birthday attack – find two messages that have the same hash but only differ by say spaces at the end of the line, and some other key part like dollar amount. Then when you get Alice to sign document A, the signature will be the same for document B (as Alice is signing the hashes and the hashes are the same)
- Public Key Infrastructure – how to ensure that Bob’s public key really belongs to the Bob you want to communicate with (tries to solve the key distribution problem).
- Public Key Certificates
- Certificate distribution (X.509, GPG)
- Most cryptosystems use public-key crypto just to exchange the symmetric key shared key, and then both parties this shared key to communicate with symmetric-key crypto. These systems are known as hybrid cryptosystems. This is done for mainly two reasons,
- public-key algorithms are usually around 1000 times slower than symmetric algorithms.
- public-key algorithms are vulnerable to chosen-plain text attacks.
- Cryptanalysis is about determining the plaintext from the key.
- Authentication
Extra notes from Schinder 2nd Ed.
- Types of attacks,
- cipher-text only
- known plain text
- chosen plain text
- adaptive chosen plain text (you can modify your next choice based on the results of the previous choice)
- chosen cipher text
- known key relationship
- rubberhose (get the person who knows the key to reveal it)
- Substitution ciphers
- Simple (monoalphabetic cipher)
- A → 2
B → 3
C → 1
…
- A → 2
- Homophonic (where multiple options available such as 5,2 one is chosen at random)
- A → 5,2
B → 1,3
C → 4
…
- A → 5,2
- Polygram
- ABC → 819
ABB → 234
ABA → 567
ACA → 587
…
- ABC → 819
- Polyalphabetic (simple substitution cipher, but the mapping also depends on the position of the input character in the plain text), examples include,
- Caesar cipher – shift each letter forward or back by K. eg. if K = 1, A → B, B → C …
- rot13
- Vigenere cipher – align the repeated key K over the plaintext
- These can be attacked by statistical cryptanalysis of the letter frequency
- Simple (monoalphabetic cipher)
- Transposition Ciphers – the order of the characters is changed (rotor machines such as the Enigma did this)
- eg. write across, but read down
HELLO WORLD THISI SSOME
encrypts to HWTSEOHSLRIOLLSMODIE
- eg. write across, but read down
- One time pads
- One-way hash function (also known as message digest, fingerprint, cryptographic checksum)
- pre-image → f(x) → hash value
- A hash function is collision free if it is hard (ie. at best becomes brute force) to generate two pre-images with the same hash value.
- Also a single bit change in the pre-image should on average change half of the bits in the hash value.
- Types of random sequences,
- Pseudo-random (looks random, good for applications like writing an random AI game agent)
- Cryptographically secure pseudo-random (unpredictable)
- True randomness (cannot be reproduced with the same inputs)
- Zero-knowledge proofs – proving to someone that you know something without revealinfg them what that something is. Two types,
- Interactive
- Non-interactive
RSA
Choose two primes p and q and let n = pq. Choose e such that e and (p – 1)(q – 1) are relatively prime (ie. no common factor and both prime numbers). Let d be a solution of ed = 1 mod (p-1)(q-1). Public key 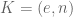
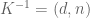

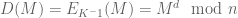
Access Control
- “An access control policy is a description of who may access what (and how).”
- Principle of least privilege – “The powers that an agent in the system is given should be the minimum that they need to have to play their assigned role in the system.”
- AC can be done at many levels (eg. hardware, os, database, network, application…)
- Managing Subjects, Objects and Operations. (can use Groups or Roles to classify subjects)
- Access Control Matrix (central database of all objects, subjects and operations permitted)
- Access Control List (store permissions with object)
- Capabilities (store permissions with subject)
- Mandatory AC – central entity sets the AC.
- Multi-level (eg. top secret, secret, unclassified labels…)
- Bell-LaPadula – no read up, no write down.
- Multi-level (eg. top secret, secret, unclassified labels…)
- Discretionary – each object has an owner, and the owner sets the AC.
- Commercial Policies
- Chinese Wall – eg set up rules like if a subject can access X they cannot access Y.
- Dual Control – need two people together to modify X, they cannot do it on their own.
- Reference Monitor – some entity that sits between the subjects and objects to implement some policy (relies on trusted entity)
Elections
You want your elections to be,
- verifiable – so the voter can check that their vote was indeed counted (and if possible check that everyone else’s vote was counted correctly)
- correct – votes are counted correctly and the results match calculated correctly
- secret (ie. no one knows how you vote, so that you cannot be coerced)
- coercion free (so you want to be recite free)
(additional notes, but don’t really need to know for exam)
- True Democracy (like the Greek’s assembly)
- Representative Democracy (where we vote in someone to represent us)
- Participatory Democracy (where we represent ourself an all have equal say)
- Australian Federal Elections are subject to the Mafia problem. Because we have preferential voting that is you can order your preferences that means that for n candidates there are n! ways of voting. So if there are enough candidates and few enough people you can coerce a person into using a specific voting pattern which you can then verify that they indeed did vote that way.
- An alternative attack would be to obtain a blank voting paper, fill it in the way you want it to be give it to someone and tell them to submit it and return you a blank one. Although the attacker won’t know if the victim has scribbled it out to make it invalid, but at least the attacker has prevented someone from voting.
Security Architecture
Security Design Principles:
- Economy of Mechanism – keep things simple
- Fail-safe defaults
- Complete Mediation – every access request checked
- Open design, ie. Kerckhoffs’ Principle: Keep the key secret, don’t rely on keeping the algorithm secret.
- Separation of Privilege
- Least Privilege
- Least common mechanism
- Psychological acceptability
Defence in depth – use many layers of security (or many security perimeters in layers)
Human Factors
- People are trusting
- People are lazy (to read the manual or change factory defaults)
- People are greedy (will exploit the system if given the chance)
- People are forgetful (forget to revoke access when terminating employees)
- People are selfish
- People are stick-beaks (eg. Medicare employees accessing client data for personal interest)
Some strategies for reducing the risk,
- logging of insider’s actions
- honeypots for insiders (eg. fake web server running on the network, or fake data in the database)
- security policy for staff to follow
Risk
Risk is not something I would have thought to be in a security course, but now that I think about it there are few if any bullet proof systems, so there is always some risk.
Whether it be secure communication (there is always some risk that an eavesdropper cracks your cryto and reads the message, so its important to weigh up those risks to decide if its worth sending the message in the first place), or be it running a web server (you cannot be sure that your web server doesn’t have bugs, or even if you have verified the code to be matching the vulnerability free specification other things can happen like, has your CPU been verified to be bug free, are you sure that a cosmic ray won’t flip a bit and subsequently create a vulnerability). So weighing up the risks involved is important to decide how much time and effort you devote to securing a system, or how the system is designed to work.
Business Risk Concepts
- Exposure – what is the worst case scenario (or loss)
- Volatility – how predictable is the loss
- Probability – how likely is that loss
Degree of Risk
<-- Probability --> High Exposure/ | High Exposure/ /\ Low Probability | High Probability || ----------------------------------- Exposure Low Exposure/ | Low Exposure/ || Low Probability | High Probability \/
Exposure – how widespread is the system?
Probability – how easy is it to exploit the system, and how great is the incentive to do so (which relates to how valuable the assets you are protecting are)?
Risk management
- Example. The risk of viruses; the mitigation strategy may be to use anti-virus detection, but the residual risk is zero-day attacks.
- Carry the risk – just accept it.
- Balancing the risk – eg. data backups at multiple locations, distributed servers at multiple locations (perhaps even running different systems, so for instance if you want to keep your web site up and running you may load balance between both a Linux box running Apache, and a windows box running IIS, so that an attack found in one is not likely to be present in the other so the attacker can’t take both offline with the one attack.)
- Mitigate it – reduce the risk
- Transfer the risk – eg. in finance, get insurance
Computer Graphics Notes
Not really complete…
Colour notes here, transformations notes here.
Parametric Curves and Surfaces
Parametric Representation
eg.

Continuity
Parametric Continuity
- If the first derivative of a curve is continuous, we say it has C1 continuity.
Geometric Continuity
- If the magnitude of the first derivative of a curve changes but the direction doesn’t then, we say it has G1 continuity.
- Curves need G2 continuity in order for a car to drive along them. (ie. not instantly change steering wheel angle at any points).
Control Points
Control points allow us to shape/define curves visually. A curve will either interpolate or approximate control points.
Natural Cubic Splines

- Interpolate control points.
- A cubic curve between each pair of control points
- Four unknowns,
-
- interpolating the two control points gives two,
- requiring that derivatives match at end of points of these curves gives the other two.
-
- Moving one control point changes the whole curve (ie. no local control over the shape of the curve)
Bezier Curve

This Bezier curve shown has two segments, where each segment is defined by 4 control points. The curve interpolates two points and approximates the other two. The curve is defined by a Bernstein polynomial. In the diagram changing points 1 and 2 only affects that segment. Changing the corner points (0 and 3) each only affect the two segments that they boarder.
Some properties of Bezier Curves:
- Tangent Property. Tangent at point 0 is line 0 to 1, similarly for point 3.
- Convex Hull Property. The curve lies inside the convex hull of the control points. (The corollary of this is if the control points are colinear, the curve is a line.)
- They have affine invariance.
- Can’t fluctuate more than their control polygon does.
- Bezier’s are a special case of B-spline curves.

We can join two Bezier curves together to have C1 continuity (where B1(P0, P1, P2, P3) and B2(P0, P1, P2, P3)) if P3 – P2 = P4 – P3. That is P2, P3, and P4 are colinear and P3 is the midpoint of P2 and P4. To get G1 continuity we just need P2, P3, and P4 to be colinear. If we have G1 continuity but not C1 continuity the curve still won’t have any corners but you will notice a “corner” if your using the curve for something else such as some cases in animation. [Also if the curve defined a road without G1 continuity there would be points where you must change the steering wheel from one rotation to another instantly in order to stay on the path.]
De Casteljau Algorithm
De Casteljau Algorithm is a recursive method to evaluate points on a Bezier curve.

To calculate the point halfway on the curve, that is t = 0.5 using De Casteljau’s algorithm we (as shown above) find the midpoints on each of the lines shown in green, then join the midpoints of the lines shown in red, then the midpoint of the resulting line is a point on the curve. To find the points for different values of t, just use that ratio to split the lines instead of using the midpoints. Also note that we have actually split the Bezier curve into two. The first defined by P0, P01, P012, P0123 and the second by P0123, P123, P23, P3.
Curvature
The curvature of a circle is 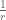
The curvature of a curve at any point is the curvature of the osculating circle at that point. The osculating circle for a point on a curve is the circle that “just touches” the curve at that point. The curvature of a curve corresponds to the position of the steering wheel of a car going around that curve.
Uniform B Splines
Join with C2 continuity.
Any of the B splines don’t interpolate any points, just approximate the control points.
Non-Uniform B Splines
Only invariant under affine transformations, not projective transformations.
Rational B Splines
Rational means that they are invariant under projective and affine transformations.
NURBS
Non-Uniform Rational B Splines
Can be used to model any of the conic sections (circle, ellipse, hyperbola)
=====================
3D
When rotating about an axis in OpenGL you can use the right hand rule to determine the + direction (thumb points in axis, finger indicate + rotation direction).
We can think of transformations as changing the coordinate system, where (u, v, n) is the new basis and O is the origin.

This kind of transformation in is known as a local to world transform. This is useful for defining objects which are made up of many smaller objects. It also means to transform the object we just have to change the local to world transform instead of changing the coordinates of each individual vertex. A series of local to world transformations on objects builds up a scene graph, useful for drawing a scene with many distinct models.
Matrix Stacks
OpenGL has MODELVIEW, PROJECTION, VIEWPORT, and TEXTURE matrix modes.
- glLoadIdentity() – puts the Identity matrix on the top of the stack
- glPushMatrix() – copies the top of the matrix stack and puts it on top
- glPopMatrix()
For MODELVIEW operations include glTranslate, glScaled, glRotated… These are post multiplied to the top of the stack, so the last call is done first (ie. a glTranslate then glScaled will scale then translate.).
Any glVertex() called have the value transformed by matrix on the top of the MODELVIEW stack.
Usually the hardware only supports projection and viewport stacks of size 2, whereas the modelview stack should have at least a size of 32.
The View Volume
Can set the view volume using,(after setting the the current matrix stack to the PROJECTION stack
- glOrtho(left, right, bottom, top, near, far)

(Source: Unknown) - glFrustum(left, right, bottom, top, near, far)

(Source: Unknown) - gluPerspective(fovy, aspect, zNear, zFar)

(Source: Unknown)



In OpenGL the projection method just determines how to squish the 3D space into the canonical view volume.
Then you can set the direction using gluLookAt (after calling one of the above) where you set the eye location, a forward look at vector and an up vector.
When using perspective the view volume will be a frustum, but this is more complicated to clip against than a cube. So we convert the view volume into the canonical view volume which is just a transformation to make the view volume a cube at 0,0,0 of width 2. Yes this introduces distortion but this will be compensated by the final window to viewport transformation.
Remember we can set the viewport with glViewport(left, bottom, width, height) where x and y are a location in the screen (I think this means window, but also this stuff is probably older that modern window management so I’m not worrying about the details here.)
Visible Surface Determination (Hidden Surface Removal)
First clip to the view volume then do back face culling.
Could just sort the polygons and draw the ones further away first (painter’s algorithm/depth sorting). But this fails for those three overlapping triangles.
Can fix by splitting the polygons.
BSP (Binary Space Partitioning)
For each polygon there is a region in front and a region behind the polygon. Keep subdividing the space for all the polygons.
Can then use this BSP tree to draw.
void drawBSP(BSPTree m, Point myPos{
if (m.poly.inFront(myPos)) {
drawBSP(m.behind, myPos);
draw(m.poly);
drawBSP(m.front, myPos);
}else{
drawBSP(m.front, myPos);
draw(m.poly);
drawBSP(m.behind, myPos);
}
}
If one polygon’s plane cuts another polygon, need to split the polygon.
You get different tree structures depending on the order you select the polygons. This does not matter, but some orders will give a more efficient result.
Building the BSP tree is slow, but it does not need to be recalculated when the viewer moves around. We would need to recalculate the tree if the polygons move or new ones are added.
BSP trees are not so common anymore, instead the Z buffer is used.
Z Buffer
Before we fill in a pixel into the framebuffer, we check the z buffer and only fill that pixel is the z value (can be a pseudo-depth) is less (large values for further away) than the one in the z buffer. If we fill then we must also update the z buffer value for that pixel.
Try to use the full range of values for each pixel element in the z buffer.
To use in OpenGL just do gl.glEnable(GL.GL_DEPTH_TEST) and to clear the z-buffer use gl.glClear(GL.GL_DEPTH_BUFFER_BIT).
Fractals
L-Systems
Line systems. eg. koch curve
Self-similarity
- Exact (eg. sierpinski trangle)
- Stochastic (eg. mandelbrot set)
IFS – Iterated Function System
================================================
Shading Models
There are two main types of rendering that we cover,
- polygon rendering
- ray tracing
Polygon rendering is used to apply illumination models to polygons, whereas ray tracing applies to arbitrary geometrical objects. Ray tracing is more accurate, whereas polygon rendering does a lot of fudging to get things to look real, but polygon rendering is much faster than ray tracing.
- With polygon rendering we must approximate NURBS into polygons, with ray tracing we don’t need to, hence we can get perfectly smooth surfaces.
- Much of the light that illuminates a scene is indirect light (meaning it has not come directly from the light source). In polygon rendering we fudge this using ambient light. Global illumination models (such as ray tracing, radiosity) deal with this indirect light.
- When rendering we assume that objects have material properties which we denote k(property).
- We are trying to determine I which is the colour to draw on the screen.
We start with a simple model and build up,
Lets assume each object has a defined colour. Hence our illumination model is 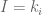
Now we add ambient light into the scene. Ambient Light is indirect light (ie. did not come straight from the light source) but rather it has reflected off other objects (from diffuse reflection). 
Next we use the diffuse illumination model to add shading based on light sources. This works well for non-reflective surfaces (matte, not shiny) as we assume that light reflected off the object is equally reflected in every direction.
Lambert’s Law
“intensity of light reflected from a surface is proportional to the cosine of the angle between L (vector to light source) and N(normal at the point).”
Gouraud Shading
Use normals at each vertex to calculate the colour of that vertex (if we don’t have them, we can calculate them from the polygon normals for each face). Do for each vertex in the polygon and interpolate the colour to fill the polygon. The vertex normals address the common issue that our polygon surface is just an approximation of a curved surface.
To use gouraud shading in OpenGL use glShadeModel(GL_SMOOTH). But we also need to define the vertex normals with glNormal3f() (which will be set to any glVertex that you specify after calling glNormal).
Highlights don’t look realistic as you are only sampling at every vertex.
Interpolated shading is the same, but we use the polygon normal as the normal for each vertex, rather than the vertex normal.
Phong Shading
Like gouraud, but you interpolate the normals and then apply the illumination equation for each pixel.
This gives much nicer highlights without needing to increase the number of polygons, as you are sampling at every pixel.
Phong Illumination Model
Diffuse reflection and specular reflection.

- Components of the Phong Model (Brad Smith, http://commons.wikimedia.org/wiki/File:Phong_components_version_4.png)


(Source: COMP3421, Lecture Slides.)

n is the Phong exponent and determines how shiny the material (the larger n the smaller the highlight circle).
Flat shading. Can do smooth shading with some interpolation.
If you don’t have vertex normals, you can interpolate it using the face normals of the surrounding faces.
Gouraud interpolates the colour, phong interpolates the normals.
Attenuation
inverse square is physically correct, but looks wrong because real lights are not single points as we usually use in describing a scene, and
For now I assume that all polygons are triangles. We can store the normal per polygon. This will reneder this polygon, but most of the time the polygon model is just an approximation of some smooth surface, so what we really want to do is use vertex normals and interpolate them for the polygon.
Ray Tracing
For each pixel on the screen shoot out a ray and bounce it around the scene. The same as shooting rays from the light sources, but only very few would make it into the camera so its not very efficient.
Each object in the scene must provide an intersection(Line2D) function and a normal (Point3D) function
Ray Tree
Nodes are intersections of a light ray with an object. Can branch intersections for reflected/refracted rays. The primary ray is the original ray and the others are secondary rays.
Shadows
Can do them using ray tracing, or can use shadow maps along with the Z buffer. The key to shadow maps is to render the scene from the light’s perspective and save the depths in the Z buffer. Then can compare this Z value to the transformed Z value of a candidate pixel.
==============
Rasterisation
Line Drawing
DDA
- You iterate over x or y, and calculate the other coordinate using the line equation (and rounding it).
- If the gradient of the line is > 1 we must iterate over y otherwise iterate over x. Otherwise we would have gaps in the line.
- Also need to check if x1 is > or < x2 or equal and have different cases for these.
Bresenham
- Only uses integer calcs and no multiplications so its much faster than DDA.
- We define an algorithm for the 1st octant and deal with the other octant’s with cases.
- We start with the first pixel being the lower left end point. From there there are only two possible pixels that we would need to fill. The one to the right or the one to the top right. Bresenham’s algorithm gives a rule for which pixel to go to. We only need to do this incrementally so we can just keep working out which pixel to go to next.
- The idea is we accumulate an error and when that exceeds a certain amount we go up right, then clear the error, other wise we add to the error and go right.
We use Bresenham’s algorithm for drawing lines this is just doing linear interpolation, so we can use Bresenham’s algorithm for other tasks that need linear interpolation.
Polygon Filling
Scan line Algorithm
The Active Edge List (AEL) is initially empty and the Inactive Edge List (IEL) initially contains all the edges. As the scanline crosses an edge it is moved from the IEL to the AEL, then after the scanline no longer crosses that edge it is removed from the AEL.
To fill the scanline,
- On the left edge, round up to the nearest integer, with round(n) = n if n is an integer.
- On the right edge, round down to the nearest integer, but with round(n) = n-1 if n is an integer.
Its really easy to fill a triangle, so an alternative is to split the polygon into triangles and just fill the triangles.
===============
Anti-Aliasing
Ideally a pixel’s colour should be the area of the polygon that falls inside that pixel (and is on top of other polygons on that pixel) times the average colour of the polygon in that pixel region then multiply with any other resulting pixel colours that you get from other polygons in that pixel that’s not on top of any other polygon on that pixel.
Aliasing Problems
- Small objects that fall between the centre of two adjacent pixels are missed by aliasing. Anti-aliasing would fix this by shading the pixels a gray rather than full black if the polygon filled the whole pixel.
- Edges look rough (“the jaggies”).
- Textures disintegrate in the distance
- Other non-graphics problems.
Anti-Aliasing
In order to really understand this anti-aliasing stuff I think you need some basic understanding of how a standard scene is drawn. When using a polygon rendering method (such as is done with most real time 3D), you have a framebuffer which is just an area of memory that stores the RGB values of each pixel. Initially this framebuffer is filled with the background colour, then polygons are drawn on top. If your rending engine uses some kind of hidden surface removal it will ensure that the things that should be on top are actually drawn on top.
Using the example shown (idea from http://cgi.cse.unsw.edu.au/~cs3421/wordpress/2009/09/24/week-10-tutorial/#more-60), and using the rule that if a sample falls exactly on the edge of two polygons, we take the pixel is only filled if it is a top edge of the polygon.

- Anti-Aliasing Example Case. The pixel is the thick square, and the blue dots are samples.
No Anti-Aliasing
With no anti-aliasing we just draw the pixel as the colour of the polygon that takes up the most area in the pixel.
Pre-Filtering
- We only know what colours came before this pixel, and we don’t know if anything will be drawn on top.
- We take a weighted (based on the ratio of how much of the pixel the polygon covers) averages along the way. For example if the pixel was filled with half green, then another half red, the final anti-aliased colour of that pixel would determined by,
Green (0, 1, 0) averaged with red (1, 0, 0) which is (0.5, 0.5, 0). If we had any more colours we would then average (0.5, 0.5, 0) with the next one, and so on. - Remember weighted averages,
where you are averagingand
with weights
and
respectively.
- Pre-filtering is designed to work with polygon rendering because you need to know the ratio which by nature a tracer doesn’t know (because it just takes samples), nor does it know which polygons fall in a given pixel (again because ray tracers just take samples).
- Pre-filtering works very well for anti-aliasing lines, and other vector graphics.
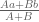
Post-Filtering
- Post-filtering uses supersampling.
- We take some samples (can jitter (stochastic sampling) them, but this only really helps when you have vertical or horizontal lines moving vertically or horizontally across a pixel, eg. with vector graphics)
of the samples are Green, and
are red. So we use this to take an average to get the final pixel colour of
- We can weight these samples (usually centre sample has more weight). The method we use for deciding the weights is called the filter. (equal weights is called the box filter)
- Because we have to store all the colour values for the pixel we use more memory than with pre-filtering (but don’t need to calculate the area ratio).
- Works for either polygon rendering or ray tracing.

Can use adaptive supersampling. If it looks like a region is just one colour, don’t bother supersampling that region.
OpenGL
Often the graphics card will take over and do supersamling for you (full scene anti aliasing).
To get OpenGL to anti-alias lines you need to first tell it to calculate alpha for each pixel (ie. the ratio of non-filled to filled area of the pixel) using, glEnable(GL_LINE_SMOOTH) and then enable alpha blending to apply this when drawing using,
glEnable(GL_BLEND); glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
You can do post-filtering using the accumulation buffer (which is like the framebuffer but will apply averages of the pixels), and jittering the camera for a few times using accPerspective.
Anti-Aliasing Textures
A texel is a texture pixel whereas a pixel in this context refers to a pixel in the final rendered image.
When magnifying the image can use bilinear filtering (linear interpolation) to fill the gaps.
Mip Mapping
Storing scaled down images and choose closes and also interpolate between levels where needed. Called trilinear filtering.
Rip Mapping helps with non uniform scaling of textures. Anisotropic filtering is more general and deals with any non-linear transformation applied to the texture
Double Buffering
We can animate graphics by simply changing the framebuffer, however if we start changing the framebuffer and we cannot change it faster than the rate the screen will display the contents of the frame buffer, it gets drawn when we have only changed part of the framebuffer. To prevent this, we render the image to an off screen buffer and when we finish we tell the hardware to switch buffers.
Can do on-demand rendering (only refill framebuffer when need to) or continuois rendeing (draw method is called at a fixed rate and the image is redrawn regardless of whether the image needs to be updated.)
LOD
Mip Mapping for models. Can have some low poly models that we use when far away, and use the high res ones when close up.
Animation
Key-frames and tween between them to fill up the frames.
===============
Shaders
OpenGL 2.0 using GLSL will let us implement out own programs for parts of the graphics pipeline particularly the vertex transformation stage and fragment texturing and colouring stage.
Fragments are like pixels except they may not appear on the screen if they are discarded by the Z-buffer.
Vertex Shaders
- position tranformation and projection (set gl_Position), and
- lighting calculation (set gl_FrontColor)
Fragment Shaders
- interpolate vertex colours for each fragment
- apply textures
- etc.
set gl_FragColor.
Human Computer Interaction Notes
These notes are based around my COMP3511 course.
Interaction Design (+Scenarios)
- Interaction Design is about creating user experiences that enhance and augment the way people work, communicate, and interact.1
- Interaction Design has a much wider scope than Human Computer Interaction. ID is concerned with the theory and practice of designing user experiences for any technology or system, whereas HCI has traditionally been focused on/surrounding humans and computers specifically.
- Interaction Design involves understanding the requirements.
- Requirements can be functional (what should it do) or non-functional (what are the constraints). The usability principles (heuristics) fit into the non-functional requirements.
- User Profiles are a set of persona’s. A persona is a short description of a fictional user.
- Scenarios
- Activity Scenario (narrative based on user’s requirements)
- Used at the beginning of the design process.
- Who, When, What, Why
- Not technical/no specific details (re: does not presuppose the interface)
- From the users perspective
- Use Case Scenario (narrative of how the user uses the interface to fulfil their goal)
- Include the users goals but focus on the user/computer interaction (re: talk about the technology)
- Basically is a description of the use case diagram.
- Do these scenarios after you figure out the requirements
- Different users would have different use cases, we can show this with a use case diagram which shows the actors and the various use case’s that they encounter.
- Task Scenario
- Used when running a usability test. ie. give the participant a scenario before giving them a task to give them context.
- When describing a scenario, give the users goals, their context and situation. Use a narrative form.
- Activity Scenario (narrative based on user’s requirements)
Cooper et al. describe the process of interaction design as,
- Identifying needs and establishing requirements for the user experience.
- Developing alternative designs that meet those requirements.
- Building interactive versions of the designs so that they can be communicated and assessed.
- Evaluating what is being built throughout the process and the user experience it offers.
Scenarios are narratives about named people with an age. We need some background to understand where they are coming from (for instance their cultural background (eg. the US uses MM/DD/YYYY but Australia uses DD/MM/YYYY)). We try to remove incorrect assumptions about what we think a certain group of people are like. The scenario should explain their motivations and their goals.
Usability
Usability is all about producing things which are usable. Where something is usable when it meets these usability goals, however you should work out which goals are most important for the problem and focus on those first.
Usability Goals
- easy to learn
- easy to remember how to use
- effective to use
- efficient to use
- safe to use
- have good utility (providing the right kind of functionality to allow the user to achieve their goal)
User Experience Goals
- satisfying
- fun
- helpful
- motivating
- universal access (accessibility)
Heuristics (Usability Principles)
- visibility of system status (eg. busy mouse icon)
- match between system and real world (includes interface metaphors. eg. files and folders concept, “speak the user’s language” (avoid gargon that users may not understand))
- user control and freedom (includes letting the user cancel/exit. eg. can pause/cancel file transfers)
- consistency and standards (eg. consistent terminology, consistent workflows, common look and feel, GUI toolkits. eg. GNOME/GTK+)
- help and documentation
- help users recognise, diagnose and recover from errors (tell users what the problem was, why it happened and some possible solutions, using plain English. eg. recover from trash)
- error prevention (eg. move to trash first)
- recognition rather than recall (GUI applications menu as opposed to CLI)
- flexibility and efficiency of use (eg. keyboard shortcuts (helpful for experts, but hidden from novices))
- aesthetic and minimalist (uncluttered) design (maybe put rarely used info into a help page/manual rather than in the interface)
Design Principles
- visibility
- feedback (can be audio, visual…)
- affordances (clues on how to use. eg. ⋮∶affords grabable)
- consistency (includes look and feel consistency)
- mapping
- eg. which light switch controls which light
- constraints
- logical (eg. grey out menu options that are not allowed)
- physical (eg. you can’t plug a USB cable into a VGA port, c.f. you can put a DVD in a CD player)
- cultural
When designing a system we need to consider,
- who are the users,
- how will the product be used,
- where will the product be used
Identifying Needs
Requirements
When testing an interface with users/test participants, give them a high level goal and observe how they go about doing it. Don’t give them specific instructions.
Use Scenario 1: For each task identified (or major tasks, or particularly special tasks if many tasks are defined), write a description of how that user would accomplish the task independent of how they would complete it within the application.
Use Case 1: If a use scenario has been implemented, include a matching use case which describes how the task use scenario can be completed in the application. There may be branching or multiple ways to complete the task, and this is a good way to document it.
To test if something is a requirement just ask, “If I remove this, will the product still fulfil its purpose?”
Design Conceptualisation
A conceptual model is a high-level description of how a system is organised and operates. –Johnson and Henderson, 2002, p. 26
I like to think of it as this. The person coding the web browsers understands that when the users types in a URL and presses enter an HTTP GET request is sent and the response is received and the HTML is processed and displayed. There are many technical interactions and details that are happening here. But the conceptual model of this is what the average non-technical uses thinks is happening. They just have some kind of model in their head that they type the URL hit enter and get the web site displayed. Its just an abstraction of what is going on.
Interface metaphors are used as they can help the user understand and determine how an interface works. We try to use them for this purpose but just using the metaphor directly can have some negative affects (eg. if your designing a radio application for desktop PC’s, it may not be a good idea to just show an image of a real radio as the UI). We don’t want to use the metaphor to an extent that it breaks the design principles.
A classic example of a conceptual framework is that of the relation between the design of a conceptual model and the user’s understanding of it. In this framework there are three components, (Sharp et al., 2006)
- The designer’s model – the model the designer has how how the system works (or how it should work)
- The system image – how the systems actual workings are portrayed to the users through the interface, manuals, etc. (or how it is presented)
- The user’s model – how the user understands the system works (or how it is understood)

Conceptual Framework (from Norman, 1988)
The designers job is to create the system image so that the users will invoke the same conceptual model as the designer’s.
- “A good conceptual model allows us to predict the effects of our actions.” (Norman, 1988)
The interface could be made more transparent so the user can see the details of how the system works, but this is not always desirable as it may cause confusion. Also many users may not want to know all the gory details, nor should they have to know the actual implementation in order to use the system.
- You can conceptualise how a user interacts with a system in terms of their goals and what they need to do to achieve those goals.
- You can try to give the user a more correct mental model of the system by giving useful feedback based on their input and providing help and documentation.
Prototyping
- Can do low fidelity or high fidelity prototypes.
- Could use paper mockups of screens, storyboards, electronic mockup, electronic prototype…
- Make sure you iterate.
- “the best way to get a good idea is to get lots of ideas” –Linus Pauling
Using A Design Diary
- Brainstorm ideas
- Sketch interface mockups
- Sketch storyboards/work flow diagrams
Wireframes
Here is an example wireframe.

Example Wireframe from https://wiki.ubuntu.com/DesktopExperienceTeam/KarmicBootExperienceDesignSpec
Another paper prototype with a slightly higher fidelity.

An example paper prototype (from https://wiki.ubuntu.com/SoftwareStore).
Issues Table
- In this course we list the issues vertically and the participants horizontally.
- Prioritise and group the issues. (Maybe use affinity diagramming for the grouping)
Usability Testing
- Can do interviews, questionnaires, usability tests (best to run a dry run of these before you start testing on many people), interaction logging…
- The purpose of a usability test is to gather feedback from potential users about usability issues as well as ensuring that an interface can be used and works as expected.
- Testing should be done throughout the whole process during prototyping, beta versions, and deployed applications.
- According to Nielson you only need test an interface with 5 people to find 80% of the issues (see Nielsen, Usability Engineering, p173) (however to publish research 5 is statistically too small so you should use at least 10).
- When planning a test you need to define scenarios and tasks as well as deciding what to test and how to collect the results. Its a good idea to have goals that try to measure the success of the usability principles.
- Test the parts of your interface which would be used most, as well as any particularly difficult to design aspects first.
There are some legal and ethical issues to consider. The participant,
- needs to sign a consent form for you to run a test with them.
- is free to stop participating at any time.
- must be made aware of how you are observing them and what will be done with data collected. eg. is the session been recorded on video, audio, observed by people, screen captured…? Will the data be antonymous, will the anonymous results be published…
- should be made aware that you are testing the software, not them.
During a Usability Test,
- Avoid leading questions. (eg. try to avoid “How much do you like this interface?”)
- When running a usability test be careful not to bias your results. For example instead of asking the user “How would do X? when there is a button “Do X”, give them a scenario which has a goal and ask them how they would go about achieving this with the interface.
- You want the participant to “think aloud” so that you know what they are thinking when they are using the interface you are testing.
- If users are struggling give them a hint, if that doesn’t help explain the expected solution and move on, but note that they needed assistance when recording the test data.
- If a task is difficult for the user, its not the users fault, its the interface’s!
- We want to record things like time to complete the task, amount and nature of errors encountered and by who… Things that address the usability principles. You should record both these quantitative measurements and any qualitative things that you observer or the participant mentions.
After the Testing,
- Collate feedback and test data (Use an issues table to record the usability issues that the participants had.)
- Group issues and prioritise them.
- When analysing results consider,
- If a user is asked to compare two interfaces, the results may bias towards the second as they learn from their first experience.
- Can try to solve this by getting some participants to do A then B, and others B then A.
- Observing how a user interacts with an interface may change how they interact with it. (ie. they may have done things differently if they were at home, without you scrutinising their every move).
- We can try to avoid this by making the participants feel comfortable and reinforcing that we are not testing them we are testing the interface. Assure them that there are no incorrect users and don’t avoid doing things just because you know we are taking notes.
- If a user is asked to compare two interfaces, the results may bias towards the second as they learn from their first experience.
Usability Testing
When actually running a usability test you should follow a usability test plan. The test plan just details what the test facilitator should do during the test.
The usability testing procedures we used in this course are:
- Explain procedures (think aloud, data collection methods in use…)
- Make sure they agree and sign a consent for before proceeding (you keep one, they keep one)
- Run a pre-test questionnaire (used to generate a participant profile) (this helps to give you an idea on their experience level, as well as any background they may have in using similar interfaces before, as these affect how the participant performs) (best to get the participant to do this a few days before the test so that you can focus on specific tasks.)
- Introduce scenario
- Run through tasks
- Ask any post test questions
- Do they have any extra comments/debriefing
- Thank them for their time
Interviews
- Can be open ended (participant gives longer responses which may include their reasoning) or closed (list of options participant chooses from).
- When running an interview give,
- An introduction to the interview (what you are doing, purpose, what happens to the responses, how it it being recorded)
- Warm-up questions
- Main section. (use a logical sequence)
- Cool-off questions
- Closing remarks.
Questionnaires
- Participant Sample (You probably want a sample representative of your users/target users).
User Centred Design Process
The UCD process is all about focusing on the users and tasks. It also means iterate your designs often. The development is driven by users needs rather than technical concerns.
More specifically Gould and Lewis (1985) give three principles,
- Early focus on users and tasks.
- Empirical measurement.
- Iterative design.
Affinity Diagramming
- This is where we collect ideas and then group them.
- Don’t use pre-defined groups, make them up as you start sifting through the ideas.
- The idea is to organise a bunch of individual ideas into a hierarchy.
Card Sorting
- Get a bunch of people to sort cards with some idea/concept/whatever into categories and then compare how they were sorted by the different participants.
Software Lifecycles
- Waterfall
- W-model
- Spiral
- Rapid Application Development
- Star Model (evaluation at each step)
- ISO 13407 (the HCI model goes around in a circle and only exits when satisfactory)
Cognitive Load Theory
Cognition is what goes on in our brains. It includes cognitive processes such as,
- attention
- Some techniques are particularly good at grabbing attention (flashing, moving, colourful or large things). But these should be used sparingly.
- perception and recognition
- Gestalt principles of perceptual organisation. ie. we group things by proximity, similarity, closure, symmetry and continuity.

Gestalt principles of perceptual grouping. (a. you see two groups the left two and the right two; b. you see the objects in columns rather than rows; c. you group the () braces together; d. you see two curves and most people probably see the same two curves (as opposed to sharp edges that meet at the vertex))
- Gestalt principles of perceptual organisation. ie. we group things by proximity, similarity, closure, symmetry and continuity.
- memory
- learning
- reading, speaking and listening
- problem-solving, planning, reasoning and decision-making.
- automatic processes
- Stroop effect (trying to say the colour not the words eg. red green blue orange purple pink) is due to this.

Some Cognitive Load Theory
- Huge long term memory (with the information stored in schemas) and a limited working memory.
- Schemas allow us to bypass our working memory limitations by chunking information.
- They allow us to ignore the huge amount of detail coming from our senses and instead integrate with our existing schemas.
- eg. its much easier to memories SYSTEM than YSMSTE.
- “Automated Schemas”
- Worked Examples instead of Means-Ends Analysis
- Its better to give new users a quick (or even not so quick) ‘worked example’ of how the interface works/how to use it, than just let them work it out for themselves.
- Split Attention Effect
- e.g. “See figure 16.”, “Refer to page 26″… “Requires us to mentally integrate information that is physically split.”2
- Solution physically integrate the material.
- Don’t force users to recall information from a previous screen.
- The Redundancy Effect
- It is better to emit redundant information as it generally just confuses people.
- Expertise Reversal Effect
- Its better to assume your audience is novice, if you are unsure.
- Novices need lots of worked out examples
- Reduce Search (reduces cognitive load)
- By using a consistent layout
- By reducing visual clutter
- Diagrams can reduce cognitive load
- Modality Effect
- Separate working memories for audio and visual senses.
- Therefore presenting information visually and auditory allows for a greater total working memory size than just presenting it visually or auditory. (But we should consider users with disabilities, so taking advantage of this by presenting some information visually and some auditory is not a good idea)
Some HCI Applications
- The Training Wheels approach involves restricting the features of an interface for novices until they become more experienced when advanced features are enabled.
Memory
(From a psychologists perspective).
- Memory is based on your context (eg. night, bed, tired, dark, dream… ask them to recall they will often recall sleep even though it was never mentioned). Give context before this will help them store the information and recall it better.
- Miller’s theory is that only 7± 2 chunks of information can be held in short-term memory at any one time. (But this doesn’t mean say, only put seven items in any menu or something like that. This is only for short-term memory and when the information comes and goes, not when it can be rescanned.)
Long Term Memory

A Taxonomy of Memory
Explicit and Implicit Memory
“Imagine that you learn a list of items and are then required to recall or recognise them. This memory test would be accompanied by conscious awareness that you were remembering. Imagine that a considerable time later, a test of recall or recognition revealed no memory for the items. However if you were given the original list to relearn there would probably be some savings in learning time (i.e. you would take less time to learn the list the second time, oven though you were not aware of your memory of the items). This is the distinction between explicit memory, in which remembering is accompanied by either intentional or involuntary awareness of remembering, and implicit memory, in which remembering is not accompanied by awareness (Graf & Schacter 1985; Schacter 1987).” — (Walker, “Chapter 9: Memory, Reasoning and Problem Solving”. pg. 262 (sorry I don’t have the title))
Not really related, but a good thing to hear a text book say,
“Finally, some long-enduring memories are for passages that our teachers have drulled into us… The Interesting thing about these memories is that they are preserved as they were memorised, in a very literal form, in exact wordings (Rubin, 1982). The memory code is not transferred from literal to semantic. In fact, the words are often remembered mechanically, with almost no attention to their meaning.” –(Walker, “Chapter 9: Memory, Reasoning and Problem Solving”. pg. 267 (sorry I don’t have the title))
- The method of loci.
- The context that a memory is encoded, affects its retrieval. For example you may not initially recognise your neighbour on the train, as you are not used to seeing them there.
- People are much better at recognising things than recalling things.
Obstacles to Problem Solving
- Unwarranted Assumptions
- Example given in class. “A man married 20 women. yet he broke not laws and never divorced. How? He was a priest.”
- Seeing new Relationships
- Functional Fixedness
- Being an expert at a system, you may not see things that novice would see.
- You avoid using things in an unconventional way.
- New users may find new or unintended uses of the system.
- The Set Effect
- We may not notice that two similar problems actually need to be solved in different ways.
External Cognition
People use external representations to extend or support ones ability to perform cognitive activities. For example, pens and paper, calculators, etc. We do this to,
- reduce memory load
- eg. post-it notes, todo lists. But the placement of say post-it notes is also significant.
- offload computation
- eg. pen and paper to solve a large arithmetic problem (the mechanical kind).
- annotate
- modifying or manipulating the representation to reflect changes
Experts vs. Novices
- What distinguishes an expert is their large knowledge based stored in schemas.
- Declarative (facts)/procedural(how to do) knowledge.
- Skill acquisition.
- Cognitive stage (learn facts, encode declarative knowledge),
- Associative stage (procedural knowledge),
- Autonomous stage.
- Novices tend to use ends-means analysis (uses a lot of trial and error) to solve problems. Experts tend to use their knowledge stored in schemas to apply and solve the problem (ie. past experience).
- In software can have novice (limited functionality) and expert modes. (Could be different applications Photoshop Elements vs. Photoshop Pro, or just hide advanced functionality for novices by default eg. >Advanced Options which is clicked to show more functions.)
- IDEA: Could provide popup hints to intermediate users to explain expert functions (eg. what’s going on under the hood), or more advanced options (eg. keyboard shortcuts).
Visual Design
- Alignment of items in an interface makes it easier for users to scan the screen.
- Grouping
- Colour
- Gestalt Principles
- Menu design (see ISO 9241)
- Three types of icons,
- similar (eg. a file for a file object)
- analogical (eg. scissors for cut)
- arbitrary (eg. X for delete or close)
- Can add text near the icon to make it easier for newbie’s, but allows expert to ignore and just glance at the icon.
Internationalisation
Differences around the world,
- character set
- keyboard layout
- text direction
- language
- icons
- date, time, currency
- calendars
Internationalisation (i18n) refers to designing and developing a software product to function in multiple locales. Localisation (L10n) refers to modifying or adapting a software product to fit the requirements of a particular locale. This could include translating text, changing icons, modifying layout (eg. of dates).5
A locale is a set of conventions affected or determined by human language and customs, as defined within a particular geo-political region. These conventions include (but are not necessarily limited to) the written language, formats for dates, numbers and currency, sorting orders, etc.5
Accessibility
- Some clauses relating to requirements for Australian web sites in Australian Disability Discrimination Act (1992).
Quantification
- A way to test an interface different to usability testing.
GOMS
- Goals (eg. send an email)
- Operators (eg. double click)
- Methods (recalling what to do/how to do)
- Selection Rules (deciding which method to use to achive the goal)
Keystroke Level Model
- K (keying) – 0.2s – Press (and release) a keyboard key, or click the mouse. (Click and drag is only 1/2 K).
- P (pointing) – 1.1s – Moving the mouse to a location on the screen.
- H (homing) – 0.4s – Moving between the keyboard and mouse.
- M (mentally preparing) – 1.35s – Preparing.
- R (computer responding) – Waiting for the computer to respond.
Fitt’s Law
- In the field of ergonomics research.
- Used to predict the time to move the cursor to a target.
- A and B are experimentally determined constants. (Raskin used A = 50, B = 150).
- D is distance between start and target
- S is size of target (just dealing with 1 dimension here).
- Lesson: The larger the target the faster one can move the mouse to that location.
- Lesson: Targets at the edge of the screen have an infinite size, so they are fast to navigate to. (Problem, if you use edge bindings a lot your mouse will physically move further and further away, so the user may need to be constantly picking it up moving it)
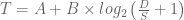
References
[1] Sharp, Rodgers, Preece. (2006) Interaction Design: Beyond human computer interaction. 2nd Ed.
[2] Marcus, Nadine. (2009) COMP3511 Cognitive Load Theory Lecture Slides.
Woo, Daniel. (2009) COMP3511 Lecture Slides.
Norman, Donald. (1988) The Design of Everyday Things.
GENL2021 – Introduction to The Australian Legal System – My Lecture Notes
I try my best to be accurate, but I would not be surprised if I have made some errors here. Also this post is still a work in progress and I’ll be making changes.
Week 1 & 2
Historical Origins of The Australian Legal System
- Common Law Legal System
- Australia has a “Common Law Legal System”. The main feature of this that separates it from other Western legal systems is the degree that it relies on precedent (through the doctrine of precedent). Under this system laws either come from Parliament, called legislation, or Courts, called case law or common law.
- I’ve come to realise that its not enough to just follow just the legislation as cases can provide extra details and insights into the legality of a matter. Furthermore you can rely on these precedents in court (although it seems they can go back on their decisions and make new precedents to override old ones, as seen with [2009] HCA 14.).
-
Institution Laws People parliament statute law members of parliament courts common law judges (most courts)/magistrates (in the local court) - Barristers are the ones in court arguing a case, eg. in litigation. Solicitors are the people you usually go to see first. They can arrange a barrister, draft wills, give legal advice, etc.
- Norman Period
- Australian Law stems from English law. English Law started out in the Norman Period.
- Feudalism
- It is a hierarchy where the king is at the top. The king own all the land and leases it out. This goes down a few levels where at the bottom you have people who are allowed to use the land if they share their crops and provide military service if necessary.

- Trials by Ordeal and Trials by Battle.
- Relied on “divine intervention” to determine the verdict.
- The Writ System (court orders…)
- Lead to Equity.
- Equity -> eg. forced to comply with the contract.
- Constitutionalism -> Can be thought of as ‘guidelines for government’
- Magna Carta
- Just an old document. But an important clause was that no one could be detained without being charged, and right to trial.
- allowing appeal against unlawful imprisonment.
- Includes,
- A right that a person can seek relief from the unlawful detention of him or herself, or of another person.
- Westminster (Parliament)
- Monarchy <-> Republic
- House of Lords/House of Commons (Upper House/Lower House)
- Parliament
- Legislative Arm -> Creation of laws
- Executive Arm -> Administration of laws
- The Bill of Rights 1689
- Non-Partisan – Not affiliated with a political party
- Security of Tenure of Judges – Protects from external pressure. ie. contractual right not to be sacked without just cause.
- Trial by Jury
- Originally (ages ago in England) the jury were locals, now they are impartial (and so are the judges) which means that they have no prior knowledge of the case.
- Saxton’s introduced compensation into the law

Week 3
Rule of Law
The rule of law had origins in the Magna Carta but its not what we now consider “the rule of law”.
The key theme of the Rule of Law is everyone is subject to the law.
Eight Ways to Make Law Fail (based on the allegory concerning Rex):
- Failure to publicise law
- Obscure law
- Retroactive law
- Contradictions in the law
- Unable to comply with the law
- Unstable daily amendments to the law
- Differences between rules/laws as announced and their administration
However at least some of these (if not all) are not law themselves. They are not in the constitution so there is nothing stopping a government from creating say retrospective law.
Law, Land & Society Before 1788
Terra Nullius is a term used to describe be land belonging to no one. The British belied Australia to be Terra Nullius as they did not see the land as having an established legal system.
Week 4
Types of Legal Systems
- Common Law
- Adversarial System (this is the type of procedure practised in common law courts)
- “relies on the skill of each advocate representing his or her party’s positions and involves an impartial person, usually a jury, trying to determine the truth of the case.” (Wikipedia.org, Adversarial System)
- Mostly done orally in the court room.
- Adversarial System (this is the type of procedure practised in common law courts)
- Civil Law
- “The Code”
- No precedence (so there is no case law)
- Inquisitive System (this is the type of procedure practised in civil law courts)
- “has a judge (or a group of judges who work together) whose task is to investigate the case” (Wikipedia.org, Inquisitive System)
- Mostly done through written submissions to the judge.
- Judge actively steers routes of evidence investigation (compared with a common law system where the lawyers do this).
- No jury (mostly).
- Communist Law
- Religious Law
- Customary Law
- eg. Aboriginal customary law
- Never written down
These legal systems “supposedly” all have the same aim.
Separation of Powers
Kept separate to balance power of any one:
- Legislative Arm (Parliament)
- Amends/Creates Laws
- Executive Arm
- Administrate Laws/Initiating Laws/Enforce laws
- Government Departments, Governor General, Police…
- Judicial Arm
- Courts/Judges (High Court…)
- Interpret laws
Jurisdiction is the power of a court to exercise judgement.
Three different types of jurisdiction,
- State vs. Federal
- Original vs. Appeal
- Civil vs. Criminal
Week 5
Federation and Laws Made By Parliament
- Australia Act 1986 (ie. federation) (according to the constitution) stipulates the number of senators and the distribution among the states.
- It was not until the UK passed their statues did Australia become legally a federation.
- Senate (Upper House) -> Scrutinise Bills
- House of Reps (Lower House) -> Draft/Introduce Bills
To get voted into the senate you need 1/6 + 1 of the votes. Once you reach this quota extra votes that would be used on you are distributed to the voters other preferences. Senators are only up for election every two elections (usually).
- Senate -> Representative of the State
- Reps -> Representative of the Country (Although its a little more detailed as they are really representative of the electorate. Because of this you can have a party with 49% of the votes but still get no members into the house of reps.)
We generally get lots of independents in the senate because people rarely vote 1. Labor 2. Liberal. If someone supports party A where B is A’s greatest competitor, most people will usually not vote for their opposition as 2, so they sometimes put some independents (remember once the quote is met, surplus votes are redistributed (either as the voter order their preferences, or if not chosen by the voter, how the party chooses)).
- With regards to politicians voting on bills, a Conscious Vote is crossing the partly line (or whatever the party decided on how they would vote) vs. a Party Vote where you (the politician) vote as your party does regardless on what you think.
Preferential Voting ensures a strong 2 party system.
Passing a Law: (Repeated for each house)
- 1st Reading
- 2nd Reading – Purpose of the bill (Sometimes used by lawyers to interpret the law).
- 3rd Reading
The Australian Constitution stipulates which matters the Commonwealth have power to make laws over and which the states have power.
Week 6
Laws Made By Courts & Precedent
An indictable offence is one where you can go to prison over it.
A case begins in the local court with committal proceedings, except for the more serious cases which begin in the supreme court. But there are some exceptions, for example certain constitutional cases will go straight to the High Court.
The different courts are listed http://www.austlii.edu.au/databases.html, although the list is not complete as you also have local courts in most states.
Local court -> District Court -> Supreme Court -> High Court.

Hierarchy of the Australian Courts
- If you don’t like the decision make by one court you can appeal to a higher one.
- For a matter to be heard in court there must be “reasonable prospects of success”.
- Civil matters claiming over $750 go straight to the supreme court.
In a criminal case beyond a reasonable doubt must be established, this is not the case in civil cases.
Because we have a common law legal system (adversarial), “the judge can only make a decision about what was herd in court and cannot make any other inquiries about the case”1.
“A judge will usually order that the costs of the successful party be paid by the unsuccessful party.”1
- Ratio decidendi
- reason for judgement.
- meaning “the reason” or “the rationale for the decision.”
- Unlike obiter dicta, the ratio decidendi is, as a general rule, binding on courts of lower jurisdiction—through the doctrine of precedent.
- Obiter dicta
- is a remark or observation made by a judge that, although included in the body of the court’s opinion, does not form a necessary part of the court’s decision.
- statements constituting obiter dicta are not binding (meaning cannot be used as argument for a precedent), although in some jurisdictions, they can be strongly persuasive.
- The High Court is the final court of appeal in Australia in matters of both State and Federal.
- Must rely on a precedent in a higher court (which implies that the precedents set by the high court are binding in all other courts).
- BUT the Full Court of the High Court is not bound by previous decisions made by the High Court, so the High Court can overrule itself.
- The Full Court of the High Court means all the judges (there are 7 and they are called justices) sit in and vote on the case, rather than just one judge per case.
- The full court of the Federal court means at least three judges sit in.
- Try mostly have an odd number of judges as when making a decision on a case, the majority prevails.
- If you don’t like the precedents try to find differences that can distinguish the cases.
- If no precedent, you can look at obiter dicta, or you can look into other jurisdictions (these are not binding but can be persuasive).
Week 7
The Legal Profession
Barristers and Solicitors are distinct parties. They have different roles and have no relation. “Solicitors have more direct contact with the clients, whereas barristers often only become involved in a case once advocacy before a court is needed by the client. Barristers are also engaged by solicitors to provide specialist advice on points of law. Barristers are rarely instructed by clients directly (although this occurs frequently in tax matters). Instead, the client’s solicitors will instruct a barrister on behalf of the client when appropriate.” (Wikipedia.org, Barrister)
In Australia Barristers are always sole traders. The research for a case is done by the solicitor who gives a brief to the barrister before they appear in the court.
Attorneys are much the same as Solicitors. The term Attorney is used more commonly in the US.
Week 9
Adversarial System
Alternative Dispute Resolution (ADR)
- Negotiation
- Informal
- Voluntary
- Both parties meet privately and try to work out a resolution without needing to go to court.
- Can lead to a settlement.
- Private. Unlike adjudication which is public. Companies that don’t want the media attention that may come from a court case, make take this option.
- Quick
- Cheaper than adjudication
- One negative for the public is that no precedent is set, so little people cannot rely on large corporations to set the precedents for them.
- Mediation
- Less formal that adjudication.
- Voluntary
- Mediator is present
- Outcome only accepted when both parties agree to it
- Individual may feel in control of the matter rather than their lawyer.
- Business relationships can be maintained
- Conciliation (only for some courts)
- Mandatory
- Mediator present, but cannot enforce/make a decision on the outcome
- Adjudication
-
- Can be lengthy taking from months to years.
- Arbitration
- Tribunals
- Courts
-
- Legislation
- The government changes the law to make a certain dispute clear.
This is very much a scale. At the top the parties very much are in control of the outcome. Whereas at the bottom they don’t have much control at all of the outcome (so long as the system is not corrupt). The top is informal, wheras the bottom is formal. At the top things are by agreement, whereas at the bottom things are much by imposition.
Other Legal Institutions
- Tribunals are set up by laws.
- They are like courts but are less formal.
- Unlike courts the strict doctorine of precedent does not apply to tribunals.
The Administrative Decisions Tribunal (ADT) is one such tribunal (they are is the NSW jurisdiction). The Administrative Appeals Tribunal is another tribunal (federal jurisdiction). As per their website “The Administrative Appeals Tribunal (AAT) provides independent review of a wide range of administrative decisions made by the Australian government and some non-government bodies. The AAT aims to provide fair, impartial, high quality and prompt review with as little formality and technicality as possible. Both individuals and government agencies use the services of the AAT.”
In most cases if you are unhappy with the tribunals decision you can appeal to a court, although there are conditions on this. For example as stated on the AAT’s web site “If you disagree with the Tribunal’s decision you may appeal to the Federal Court on a point of law. This means that the Court can only hear an appeal from the Tribunal decision if you or your adviser believe the Tribunal made a mistake in law in deciding your case. Because there are many rules about Federal Court appeals you may wish to get legal assistance.”
Week 10
Contracts and Torts
Contracts
- A contract is an agreement that is enforceable through the courts.
- Contracts can be written or verbal, but written contracts are easier to prove.
- For a contract to be valid there must be, (i.e. otherwise the contract is void, meaning its not legally binding)
- An intention by the parties to be legally bound by their promises,
- agreement by the parties on the terms of the contract,
- consideration from both sides.
- If the parties do not intend for a contract to be legally binding and there is agreement on that then the courts will honour this. (See Rose and Frank v Crompton [1923] 2 KB 261).
- When not expressly stated the courts will presume that, (but this can be rebutted, see Wakeling v Ripley (1951) 51 SR (NSW) 183)
- social, family or domestic agreements are not intended to be legally binding, and
- commercial agreements are intended to be legally binding.
Agreement of a Contract
- As mentioned for a contract to be valid it must have agreement by the parties.
- Offer and Acceptance
- An offer is made by one party, and if accepted by the other, then the contract has agreement. (I think that means, if you make an offer they say okay, you cannot go back and not be bound by the contract.)
- An “invitation to treat” is not an offer.
- Lapse of an offer
- Acceptance
- Silence is not acceptance (Felthouse v Bindley (1862) 11 CB (NS) 869) (but an act can be)
- Acceptance must be in response to an offer for the contract to be valid (R v Clarke (1927) 40 CLR 227).
There is a bunch of related conditions regarding selling of goods. See the Trade Practices Act.
Torts
- A tort is a civil wrong.
- Breach of Contract is a tort.
- Don’t need to have a contract to commit a tort. eg. Tort of Negligence.
Week 11
Criminal Law
(work in progress)
Criminal Law is meant to cover matters concerning the state.
- There are sanctions for failing to abide by the law. But there is no capital punishment in Australia.
Reasons for sanctions,
- Retribution – “they ought to suffer”
- Deterrent
- Incapacitation – protect society by locking the criminal up in jail.
- Rehabilitation – try to change them so they won’t re-offend.
Need,
- proof of crime (actus reus)
- criminal intent (mens rea) (although some “strict liability” crimes don’t need this)
Two types of offences,
- Summary offence -> Decided by a magistrate. No jury. Max 2 years imprisonment.
- Indictable offence -> most cases have a jury.
- Prosecution need to prove defendant is guilty beyond a reasonable doubt.
- A hung jury is when the jury cannot come to a unanimous (although now they will accept one who votes different to everyone else) decision.
- A persons previous criminal history can only be made known at the sentencing (after a jury has decided if they are guilty or not).
- The jury decides the defendants guilt/innocence, the judge decides the sentencing.
Sentencing,
- Could be prison.
- Could be periodic or home detention.
- Could be community service.
- Could be a fine.
- Could be discharged on a good behaviour bond.
Week 12
Mabo Decision
Native Title Act 1993 (Cth)
Wik Decision
Native Title (Amendment) Act 1998 (Cth)
References
[1] http://www.fedcourt.gov.au/videos/text_version/how_a_case_travels.html
COMP3421 – Lec 2 – Transformations
Homogeneous Coordinates
Interestingly we can use the extra dimension in homogeneous coordinates to distinguish a point from a vector. A point will have a 1 in the last component, and a vector will have a 0. The difference between a point and a vector is a bit wish washy in my mind so I’m not sure why this distinction helps.
Transforming a Point
Say we have the 2D point 

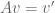
Combining Transformations
Say we want to do a translation then a rotation (A then B) on the point x. First we must do 

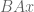

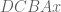
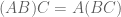
As a side note, if you express your point as a row vector (eg. 
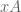

Affine Transformations
Affine transformations are a special kind of transformation. They have a matrix form where the last row is [0 … 0 1]. An affine transformation is equivalent to a linear transformation followed by a translation. That is, 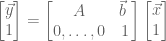
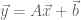
Something interesting to note is, the inverse transformation of an affine transformation is another affine transformation, whose matrix is the inverse matrix of the original. Also an affine transformation in 2D is uniquely defined by its action on three points.
From page 209 of the text (Hill, 2006), affine transformations have some very useful properties.
1. Affine Transformations Preserve Affine Combinations of Points
For some affine transformation T, points P1 and P2, and real’s a1 and b1 where a1 + b1 = 1,
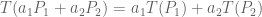
2. Affine Transformations Preserve Lines and Planes
That is under any affine transformation lines transformed are still lines (they don’t suddenly become curved), similarly planes that are transformed are still planes.
3. Parallelism of Lines and Planes is Preserved
“If two lines or planes are parallel, their images under an affine transformation are also parallel.” The explanation that Hill uses is rather good,
Take an arbitrary line A + bt having direction b. It transforms to the line given in homogeneous coordinates by M(A + bt) = MA + (Mb)t, this transformed line has direction vector Mb. This new direction does not depend on point A. Thus two different lines 


4. The Columns of the Matrix Reveal the Transformed Coordinate Frame
Take a generic affine transformation matrix for 2D,
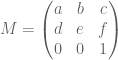
The first two columns, 

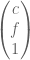
Using the standard basis vectors 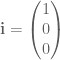



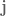
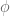
5. Relative Ratios are Preserved
6. Area’s Under an Affine Transformation
Given an affine transformation as a matrix M,

7. Every Affine Transformation is Composed of Elementary Operations
Every affine transformation can be constructed by a composition of elementary operations (see below). That is,

For a 2D affine transformation M. In 3D,

Rotations
Euler’s theorem: Any rotation (or sequence of rotations) about a point is equivalent to a single rotation about some coordinate axis through that point. Pages 221-223 of Hill give a detailed explanation of this, as well as the equations to go from one form to the other.
W2V (Window to Viewport Mapping)
A simplified OpenGL pipeline applies the modelview matrix, projection matrix, clipping, then the viewport matrix. The viewport matrix is the window to viewport map.
The window coordinate system is somewhere on the projection plane. These coordinates need to be mapped to the viewport (the area on the screen)
References
F.S. Hill, et al. (2006). Computer Graphics using OpenGL. Second Ed.
COMP3421 – Lec 1 – Colour
Colour
Pure spectral light, is where the light source has just one single wavelength. This forms monochromatic (or pure spectral) colours.

However mostly light is made up of light of multiple wavelengths so you end up with a distribution of wavelengths. You could describe colour by this frequency distribution of wavelengths. For example brown is not in the spectrum, but we can get brown from this distribution of different light wavelengths,

Spectral Distribution for a Brown Colour (http://www.cs.rit.edu/~ncs/color/a_spectr.html)
We could describe colour like this (as opposed to RGB) but human eyes perceive many different distributions (spectral density functions) as the same colour (that is they are indistinguishable when placed side by side). The total power of the light is known as its luminance which is given by the area under the entire spectrum.
The human eye has three cones (these detect light), the short, medium and long cones (we have two kinds of receptors cones and rods, rods are good for detecting in low light but they cannot detect colour or fine detail). The graph below shows how these three cones respond to different wavelengths.

So the colour we see is the result of our cones relative responses to RGB light. Because of this the human eye cannot distinguish some distributions that are different, to the eye they appear as the same color, hence you don’t need to recreate the exact spectrum to create the same sensation of colour. We can just describe the colour as a mixture of three colours.
There are three CIE standard primaries X, Y, Z. An XYZ colour has a one to one match to RGB colour. (See http://www.cs.rit.edu/~ncs/color/t_spectr.html for the formulae.)
Not all visible colours can be produced using the RGB system.
=====
Where S, P, N are spectral functions,
if S = P then N + S = N + P (ie. we can add a colour to both sides and if they were perceived the same before, they will be percieved the same after)
On one side you project 

By experimentation it was shown that to match any pure spectral colour 
=====
To detirmine the XYZ of a colour from its spectral distribution you need to use the following equations,
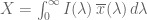


Where the 


The CIE 1931 XYZ colour matching functions. (Source: http://commons.wikimedia.org/wiki/File:CIE_1931_XYZ_Color_Matching_Functions.svg CC-BY-SA)
CIE Chromaticity Diagram
We can take a slice of the CIE space to get the CIE chromaticity diagram.


RGB
 (r, g, b) is the amount of red, green and blue primaries.
(r, g, b) is the amount of red, green and blue primaries.
CMY
CMY is a subtractive colour model (inks and paint works this way). (c,m,y) = (1,1,1) – (r,g,b).
But inks don’t always subtract well so printers usually use a black ink as well using CMYK.
HSV
The HSV colour model is really good for allowing the user to select a colour as they choose the hue (colour), saturation (how rich the colour is) and value (how dark the colour is).

HSV Colour Cone
Gamut
Gamut is the range of colours available which is represented as a triangle in the CIE Chromacity diagram. Different devices have different gamuts (for instance the printer and LCD monitor).
- Gamut Clipping – A shading in one image becomes just a solid colour in the other.
- Gamut Scaling – Shading looks the same but the size of the gamut is minimal.
Deque Implementation Design
For Assignment 1 of COMP2911 we got the task of implementing a deque, using arrays and linked lists (in Java). Here is the design I used for the implementation.
ArrayDeque
This was quite a challenge.
One approach was to have an array of size capacity, and also store some left and right index pointers to know where the deque ranges in the array.

My first idea (actually inspired by my tutor) was basically, to add to the right of the deque you start at the left and push right, to add to the left of the deque you start at the right and push left. When the two ends collide, you make a new array larger keeping the left and right parts of the deque at the leftmost and rightmost parts of the array.
 This turned out to have some problems. All worked well, except for a couple of things. Such as show here,
This turned out to have some problems. All worked well, except for a couple of things. Such as show here,
 , because now you are left in the middle and your not just pushing straight from one side to another.
, because now you are left in the middle and your not just pushing straight from one side to another.
This next situation below was also troublesome because you have to be careful where you store your left/right index pointers. You need to carefully think of what if they overlap? And if they are equal or overlap, is your arrayDeque full or empty?
 So what I did is look at the different ways to store the left/right index pointers. In all these diagrams orange means the location of the left index pointer, and the violet is the location of the right index pointer.
So what I did is look at the different ways to store the left/right index pointers. In all these diagrams orange means the location of the left index pointer, and the violet is the location of the right index pointer.
a) In this diagram I point to the next available space.
 b) In this diagram I point to the location of the most recently added item. At the very beginning I loop them over.
b) In this diagram I point to the location of the most recently added item. At the very beginning I loop them over.
 All this just lead to much confusion for me and many bugs and problems. So I had a look at an entirely new approach. It turned out much better, and I learnt that if things aren’t working out and you just keep getting lots of bugs then sometimes trying another approach can really help out. I also learnt that its really hard to know the best way to do something right from the start you really have to try something and if its not working to well than just try something else and see how it goes. So here is what I finally did.
All this just lead to much confusion for me and many bugs and problems. So I had a look at an entirely new approach. It turned out much better, and I learnt that if things aren’t working out and you just keep getting lots of bugs then sometimes trying another approach can really help out. I also learnt that its really hard to know the best way to do something right from the start you really have to try something and if its not working to well than just try something else and see how it goes. So here is what I finally did.
 Initially I just ignored the fact that I had a limited size array, and that things are actually mod array size. I just had two index pointers (shown in orange and blue) which pointed to the next free space at the left and right ends of the deque. I kept these as ints and they I don’t think of them as wrapping round. If you forget about the array based implementation and go back to the original problem of a deque you see that really all you need is a big long line with a left end and right end pointer. Now all you have to do is remember that whenever you are dealing with implementation level things such as accessing the array, to use index mod capacity, rather than the raw index value (which may be out of the array range). That and you need to have a check to know when to resize your array.
Initially I just ignored the fact that I had a limited size array, and that things are actually mod array size. I just had two index pointers (shown in orange and blue) which pointed to the next free space at the left and right ends of the deque. I kept these as ints and they I don’t think of them as wrapping round. If you forget about the array based implementation and go back to the original problem of a deque you see that really all you need is a big long line with a left end and right end pointer. Now all you have to do is remember that whenever you are dealing with implementation level things such as accessing the array, to use index mod capacity, rather than the raw index value (which may be out of the array range). That and you need to have a check to know when to resize your array.
Under this scheme the number of items in your deque is rightIndex – leftIndex – 1, therefore your array is full if and only if (rightIndex – leftIndex – 1) >= capacity. (Where capacity is the size of the array). If this is true then you need to resize your array.
The method I choose was to simply shift the deque along (either direction) so that the leftIndex is at -1.
LinkedDeque
This was much simpler. Basically I made a link object that stored an item and a left and a right pointer (to other link objects). I would store the leftmost and rightmost link items for the deque and that is all. I guess I could have stored size as part of the deque object and updated it whenever new link items were added or removed to the deque, but as we were given no requirements to do it one way or another I made it so that the size method would go though the whole deque and do a summation every time it was called.
The only thing I really had to watch was to ensure that I kept the left and right pointers for each link item up to date with changes, and this was my primary source of bugs.
SENG4921 – Oral Exam Prep
Here are the notes I made for and took into the SENG4921 oral exam.
As an after thought, you can see I wasn’t prepared for all the options but this is the best I could do in the time. Some of my arguments here may not be very valid, but this is my preparation as it stands, not a blog post into the questions (that’s my excuse for being sloppy).
Question 1: free choice
- “Each student should prepare a topic of their own free choice concerned with some aspect of software, hardware, IT professional issues or ethics. This could be —but does not have to be— based on, or derived from, the discussions, seminars, debates, student run seminars and lectures given this semester. The question should be broad enough to not overlap with the other two questions. At the examination the student will be asked to present his/her topic and discussion.
If the free choice question deals directly with one of the Seminar or Lecture questions, then this will generally eliminate that question if one of the randomly chosen 3 for question 2 or 3. Note carefully that the elimination occurs after the random choice, not before.”
After a little thought I think I will focus on DRM in this question. I think this is a good choice because,
- Its not covered in the other seminar and lecture questions,
- I know enough about the topic to be able to talk about it,
- There are actually some valid ethical questions that can be raised and debated here,
- …
So the deal is I only have 5 minutes to talk about the professional issues and ethics surrounding DRM. I need to identify the issues involved, analyse the professional and/or ethical consequences and present the outcome. I will need to be careful that I address the right things as I only have 5 minutes.
The examiners will be looking for:
- clear identification of the issues;
- analysis of the professional and/or ethical consequences;
- careful presentation of the outcomes.
There are no correct answers, but a good answer will give a clear indication of consequences and issues.
Identification of Issues
DRM is digital rights management. DRM technologies attempt to control use of digital media by preventing access, copying or conversion to other formats by end users.
- DRM is used to bypass existing copyright laws and create your own. Content protected by DRM uses software or hardware measures to prevent unauthorised use of such content. An example is protected music purchased from the iTunes music store. The music is usually encoded using AAC, however on top of this it is encrypted. In simple terms you can only play this music on Apple approved devices. So you cannot play that music on a sony MP3 player, you cannot convert the music to MP3, you cannot play the music on another player on Linux, and lastly if Apple goes bust and decides not to free your music you will never be able to play the music you bought.
- How different is this to selling music using patented encoding techniques. No one else is allowed to make a player except you.
- I mentioned this bypasses existing copyright laws. An example of this is say you want to use a segment of the content you bought which is protected by DRM but the use of the segment is permitted under copyright laws. Regardless of the law you can’t use the material either because you can’t crack the DRM or even if you can, the process of doing so is illegal.
- Also most DRM systems are not set to expire when they are supposed to fall into the public domain. Thus the work may be public domain but no one can access it as its encrypted with some DRM mechanism and no keys no longer available. This undermines the concept of the public domain.
Lastly DRM systems do not work, as most have been cracked. Once the DRM has been cracked by one person (who may be an expert) then can distribute this clean version to all over say BitTorrent. DVD’s CSS was cracked,
From personal experience a while ago I downloaded an e-book (actually a standards document) from the UNSW library/publisher of the standard. It was a PDF document and they told me that it would expire after a week or so. It turns out that it used some JavaScript hide the text when the system date was at whatever was a week after the PDF was downloaded (so the web server was creating the PDF on the fly putting the expiry date and the download details into the PDF). This could be easily bypassed by disabling JavaScript, using a free PDF reader that does not support JavaSript, and so on. Furthermore you could easily use some software to extract the content of the PDF and resave it without the DRM. (Will I go to jail if I ever vist the US because of the DMCA?? Or even from Australian laws?)
Professional and/or ethical consequences
Ken noted in his introduction article that “In this course, we will be particularly concerned with developing your capacity to reason about the possible outcomes.” Hence I will try to focus on the affects/consequences of DRM. Taking a consequential approach to ethical thinking requires one to consider the possible consequences. So some consequences of DRM that should be addressed when taking a ethical approach to DRM are,
- Legitimate users soon find out that they can only use the products they thought they bought in situations that are approved. eg. you find out that your iTunes music won’t play on Linux.
- Consumers become locked in to one vendor. eg. they may have purchased $100 worth of music, but they find they must buy an Apple MP3 player to use it and cannot shop around. Companies can use this advantage to raise the prices of their products to above market value.
- DRM systems that require a ‘call back’ over the internet to some key server won’t work if the company goes bust. Hence if the company goes, so does all your music.
- Many consumers will be driven to consume pirated material as its generally DRM free so less hassles.
- The public may turn against corporations as a whole, due to those that have abused their honesty and good will. People may loose trust in companies and no longer purchase any material and just obtain pirated materials instead.
- Consumers/public may feel coned and abused.
These are all possible outcomes, yet they may not all be an ethical concern. This depends on your individual ethical principles. For me if DRM leads people to move to pirated material rather than paying the owner, then this under my ethical principles this is not a concern. This is strictly a business move and the consumer will not be harmed by doing this. If the company doesn’t want people to pirate the matrial instead of buying it then they can simply remove their DRM and sell it DRM free.
But from a utilitarian perspective, DRM does little to stop the original creator receiving remuneration (if anything it may result in less remuneration), instead it causes great unhappiness. In this respect it is unethical.
As Cohen outlined professions come with these extra “professional” responsibilities. Including “public interest is paramount”, public trust, but also client’s interests. Most (if not all) DRM systems are not in the public’s interest. They are riddled with problems and do very little to stop piracy. They turn honest customers into outlaws. The key thing that consumers need to be aware of is they are not purchasing products from the iTunes store rather they are purchasing a licence to use the music in a restricted set of conditions.
Question 2: Seminar Questions
1. “Engineering”
I think Wikipedia’s summary of Engineering describes what is generally understood by the term ‘Engineering’.
Engineering is the application of scientific and technical knowledge to solve human problems. Engineers use imagination, judgement, reasoning and experience to apply science, technology, mathematics, and practical experience. The result is the design, production, and operation of useful objects or processes.
Of course as a profession it comes with all the things that make it a professions such as responsibility to the public, client’s interest, public trust, an so on.
Software and Computer Engineering can claim to be engineering professions as they meet this description of Engineering that I just quoted. Software and Computer Engineers apply scientific (mostly mathematical, or even Computer Science if you want) and technical knowledge to solve problems. They use experience and so no to apply this to the task at hand. They also do a lot of design work and the actual production of the software/hardware.
Computer programming vs. Software Engineering vs. Software Development
As a job title. Sure your official job title may be “Computer Programmer” or you may graduate with a “Computer Science” degree. That doesn’t mean you never do any “engineering”.
====
My opinion of what is generally understood by “Engineering” as a profession is (to quote Wikipedia here), “Engineering is the application of scientific and technical knowledge to solve human problems. Engineers use imagination, judgement, reasoning and experience to apply science, technology, mathematics, and practical experience. The result is the design, production, and operation of useful objects or processes.” And of course as a profession it comes with all the things that make it a professions such as responsibility to the public, client’s interest, public trust, an so on.
======
2/3. ACM Code of Ethics/Therac 25
- The ACM Code of Ethics and Professional Conduct has the general ethical principles which ACM members must abide to. It also has the code of conduct part called ‘more specific professional responsibilities’ tell you what you should do in particular (but still general) situations.
- Section 1 Ethical Principles
- Contribute to society and human well-being.
- Avoid harm to others
- Be honest and trustworthy (was Cindy honest to her superiors about the tests?)
- Be fair and take action not to discriminate
- respect privacy
- honour confidentiality
- Section 2 Specific Prof Responsibilities
- professional competence
- Give comprehensive and thorough evaluations of computer systems and their impacts, including analysis of possible risks.
- “computing professionals must minimise malfunctions by following generally accepted standards for system design and testing.”
- Access computing and communication resources only when authorised to do so.
- Section 1 Ethical Principles
- Killer Robot
- Randy Samuels
- Cindy
- The Therac 25 accidence were exactly that, they were accidents.
- The people involved were involved appear to have acted as per the ACM Code of Ethics and Professional Conduct.
- Sure they could have done things better. Improved processes, done more checks, get it independently tested, acted on patient complaints.
- Really?
4. Technical Issues with the Therac 25 Case
- Therac 25 was a machine for treating cancer
- Had no mechanical locks like previous models
- Reused software designed for older models
- relied more on software than hardware (did they take this into account when designing the software?)
- investigations only began after several accidents
- causes
- software not independently tested
- user manual did not explain certain errors
At the end of the day (as with many famous disasters) there were many times where if something was done better the problem may not have occured.
6. Killer Robot
- Cindy Yardley – Faked software tests to save her co-workers jobs.
- Knowingly let the product ship with flaws.
- Thought it would be okay, but be open and let the people charge decide that.
- —
- “Give comprehensive and thorough evaluations of computer systems and their impacts, including analysis of possible risks.”
Randy Samuels – Wrote the code that cause the robot to malfunction.
8. Intellectual Property
- Do people still use Windows 3.1? Can you still buy it? Its economic value now is probably close to zero. Why is it still protected then?
If copyright was designed to encourage new works then surly by freeing up old works such as Windows 3.1 gives Microsoft an incentive to make something new and better. - Creativity always builds on the past, yet we cannot make derivative works because of copyright laws.
- Data is now protected. And any situations that are not clear may take $$$’s to be decided by the courts. Need better statutory law and modern.
- Scientific knowledge. Most is public knowledge allows ideas to be examined and challenged and improved. Increasingly this is becoming private with genetic engineering.
- What if the internet was patented. Consider a) they essentially stoped all developments or b) make $$$’s from it when obviously we needn’t’ that cost for it to work. Inner workings were shared without the need for patents.
- Think much open source software.
From an ethical analysis,
- some 3rd world people have to pay to use seeds that have been freely available to them for centuries (this is very anti-utilitarian).
Affects Computer Scientists and Software Engineers.
- GIF Patent
- eg. iPhone developer not allowed to use CityRail data
- When copyright laws are used in this way to stop the spread of information then it counters many ethical principles, openness, fairness, sharing of information, helping someone when doing so will do no harm to you
From an economic view,
- Making a copy does no harm (negative benefit) to the person you copy from. Compared to stealing which takes it away from them. At most you may be removing potential sales.
9. Datavallience
Two types of dataveillance.
- Personal Surveillance (singled out)
- Mass Surveillance
Three examples,
- Government monitoring of internet traffic. (spying)
- Data collection of online services. (eg. facebook data gathering)
- Employer monitoring employee email.
Professionals have a responsibility to act in the public’s interest (as well as the clients interest). They also have codes of ethics to adhear to. Many ethical principles would lead to the conclusion that the people who are having their information monitored should be notified of this. To act in the public interest, the public needs to know when they are being monitored. This gives them the choice, to either use encryption, stop using the service, or something else. However professionals should make an exception to this rule when the matter is of national security or something other when it can be justified that not notifying is acting in the publics interest. This is what ethics is all about. Dealing with these exceptions to the rule.
- What is dataveillance?
- Is it immoral to collect data about other people?
- What personal data is currently being collected?
- What new opportunities are there to collect even more personal data?
- How can dataveillance be regulated?
- What advice would you give to non-specialists about safeguarding personal information?
It depends on the situation. The ethical approach I subscribe to is that the person who is having data collected on them, should be made aware of what is being collected, and that it is being collected.
Question 3: Lecture Questions
- give an overview of the lecture;
- describe the important professional and/or ethical ideas raised in the lecture, especially those that impact on Software/Computer Engineers and Computer Scientists;
- Important answer any specific questions attached below to the lecture.
1. Theoretical Underpinnings of Ethics
“Essentially, you are being asked to demonstrate how different ethical principles could be used to produce different outcomes. The important part of your answer will be the identification of the different principles and how your reasoning would proceed from those principles.”
Overview
- Humans around the world all tend to have the same ethical concepts. Integrity, fairness, honesty, openness…
- Relativism is doing what the culture is doing just because everyone else is doing it. This does not make it right. People are too quick to play this relative card.
- When we talk about ethics we mean prescriptive ethics. This is what you should or ought to do, compared to descriptive ethic which is what people do do.
- Ethical can be contrasted to,
- prudential (self interest)
- political (vote of opinion)
- preference (want rather than should)
- Rule, Consequences, Professional Code, law, loyalty to employer, confidentiality all factor into ethics. Rules and consequences fall into private (individual) morality, the rest is public morality which matters when you occupy a role.
- There are different levels of morality. In order,
- Obligation (signed agreement)
- Duty (eg. its your duty to treat every human with respect)
- Social Responsibility (duty without specific target)
- Minimally Decent Samaritan (go the extra mile to help them)
- Good Samaritan (someone asks you the time, you tell them)
- Heroism/Self-Sacrifice (wistleblowing)
And now on to the part relevant the the question at hand,
- Two different ethical principles are consequential (teleological) and non-consequential (deontological).
- Under the non-consequential view,
- to determine if an act is right or wrong it in fact has nothing to do with the consequences of the act. Instead it has to do with other things such as rights, duties, contracts, fairness, etc.
- Kant’s idea was that good will is what makes an act right, where good will is recognising your duty and then being able to make yourself do it (eg. you crash into a parked car you realise it is your duty to leave your details and then your able to make yourself to do that, even if you don’t want to do it).
- Under the consequential view,
- Acts are right based on their consequences.
- We have,
- Utilitarianism – “Acts are right insofar they produce happiness and they are wrong insofar as they don’t produce happiness.”
- Nationalism – “Acts are right if they are in the best interest of the nation as a whole.”
- Epistemism – “Acts are right insofar as they advance our knowledge, and they are wrong if they don’t do that.”
- Example. A dangerous criminal who commited murder and who is very likely to do it again falls into a dangerous situation (eg. is downing). It may very well be your social obligation to throw them an inflatable tube. That would be the fair thing to do, and it would be your social responsibility. However that would not be considering the consequences. Taking a consequential approach, the consequences of saving this one person may cause great unhappiness (and great risk of harm) for the people who the drowning person has threatened to kill. The ethical thing here may be to let him drown in order to save the lives of many others. But again this all depends on your ethical principles.
To make a moral judgement you need to make a judgement, have some justification for that judgement, and also have some principle that lead you to believe that that justification was right. (judgement > justification > principle) If you don’t have this, you don’t have a moral judgement.
2. Professionalism and Ethical Responsibilities
- The key thing that distinguishes professionals or a ‘profession’ is professionals have these extra public ethical responsibilities.
- act in client’s interest
- exercise of judgement
- code of ethics
- public trust
- act in public interest
- This is what separates a profession from a business (or a professional from a businessman). These extra things are their duty. Professionals have an obligation to oblige to these things. cf. businessmen are not ethically obliged to act in the public’s interest.
- They have a duty to survey the whole landscape and do what is best.
- Conflict of interest. You can’t be a profession if you have some extra incentive (eg. being paid to do something against the client and public’s interest).
“A person’s having a conflict of interest is not the same thing as a person’s being affected by a conflict of interest.” People who say they don’t have a conflict of interest just because they are not affected by (or more specifically their judgement is not affected by) a conflict of interest doesn’t
mean they don’t have a conflict of interest. - Codes of Ethics and Codes of Conduct. Codes of Ethics have values/principles. (eg. honesty, openness)
- Any principle/value will require judgement.
- You make a judgement on the principle/value, and in this respect Code’s of Ethics are empowering. (eg. guy here to kill someone, honesty does not require you to tell him where to find the person).
- Code’s of Conduct are different. They are not for introducing new values. They are there to remove judgement. They tell you exactly what to do in specific situations. eg. Bribes. They may say that you cannot accept any gift you receive over a given about. They take the heat off.
Other things of interest,
- “At work, you don’t leave your private, personal values at the door!” “Your ethical values must be there.”
- The answer to “Who’s to judge” is always “You, as an individual.” (from whatever perspective whether it be legal, ethical…)
3. Open source from an Economical Approach
- Software is a Collective Consumption Good. Consumption by one consumer does not reduce consumption by any other. Also “non rivalrous”.
- Software is Nonexcludable = difficult to exclude others from use
- Goods which are both lead to incentive to free ride, Results in “Market Failure”
- Argument is that, therefore software will not be produced unless there are special rights restricting the exploitation of software.
- According to this, these are not possible
- Linux, Apache, MySQL, PHP, Email, Internet protocols
Closed source (Sales Force): For every $1 spent on software development, $10 is spent on marketing
Open Source (SugarCRM): for every $4 spent on development, $1 is spent on marketing
6. Freehills Talk/Software Patents
Quick Summary
- Patents are a business tool.
- Monopoly vs. Secrecy
- Patentability (any prior art)
Ethical issues for Software Engineers/Computer Scientists
- Patents cost $$$, and take time. Is this worth it.
- What if the internet was patented. Consider a) they essentially stoped all developments or b) make $$$’s from it when obviously we needn’t’ that cost for it to work. Inner workings were shared without the need for patents.
- Think much open source software.
This comes down to your ethical principles. My ethical principle resolve around helping others, advancing knowledge, and working together for maximum benefit. So under my ethics software patents are unethical because they hinder the progress and development of (in the case of software patents), software. For example, someone patents the GIF encoding scheme, this can be used to lock out people from using this method. It also locks the scheme up so in the theoretical case where someone patents X, which lasts for 20 years. Person B invents X two years later but cannot use or distribute that invention because of the patent.
If you don’t want others exploiting or using or building on your invention then don’t share the details with anyone.
We are forgetting that many people (think Linux) don’t need the incentive of a patent to invent things or make them useful to the public. Patents hinder the publics access to certain processes.
If everyone was free to take others hard work and put it to good use, and build upon it and share that then progress would move faster than ever before.
But this is just my view of the matter. I do grant that I have this view because for me, progress (in terms of new and better software, etc) comes by people working on their own will because they want to for the fun of it (an example open source software, much of it was done with little commercial incentive). No money is wasted on lawyers who make no progress to the field. Instead everyone can work on pushing progress forward.
The ethics is solid. In fact patents were originally designed very ethically. Look at the consequential utilitarianism approach.
But things have changed. Software patents have not helped with this.
- Look at Mathematics > no patents. Much progress. Much work is based on previous work. (imagine if some theorems were ‘protected’ for 20 years and you could not discover any theorems that used that original theorem in its conception or proof)
- Have Software Patents really done what the patent was meant to do? No. The consequences of having patents was originally that the inner workings and methods of creation of an invention were published to the public for their good. But patents don’t have source code
Back to patents.
7. Law
- Statutory Law. Parliament.
- Common Law Courts.
- 4 jurisdictions
- criminal
- civil (tort and contract)
- administrative law
- equity
- litigation is the process or a lawsuit
- burden is on the plaintiff (the one brining the action)
- can be $$$
- putative damages (in contrast to compensatory damages) are not to compensate rather to reform or deter the defendant/others from doing the act/repeating it.
- Windows and the iPhone are licensed. They come with a license agreement.
Well as an ethical professional engineer you have an obligation/duty to act in the client’s and the public’s interest. As such you should notify the company of the situation and let them make a decision based on that. This is acting in the clients interest. Even with out this certain ethical principles such as openness may require you to notify the other party
Contrasted to an ordinary businessman who has no duty (thought they ought to do at least what is minimally decent) to act in the publics interest.
Different Standards when choosing to obey a law or not. Illegal? Litigation Risk? ‘Professional’ Standard(will your peers reject you)? Ethics(will your friends and children reject you)?
9. Internet Censorship
Overview
Professional/Ethical Ideas / Social/Technical
- There is a lot to talk about this topic.
- Censorship.
- Should there be any censorship?
- Internet Content Classification.
- Should there be a gov department which pro-actively classifies all the sites on the web? eg. DET. From a technical view, the web is huge and dynamic. There is no way that one gov department can keep up with this. eg. 20 hours of video is uploaded to youtube every minute.
- Should classification work on a complaint system? People who oppose could just flood it.
- Two other options.
- Community classification (rely on good faith, ie allow people to label certain URL’s as adult only… if you get enough people to ‘vote’ then the results should be good).
- Host classification. Make laws that require the content host to label any content they make available online.
- From an ethical standpoint, your ethical values/principles (mine do) may require you to at least make a reasonable attempt to provide users with classification information.
- Transparency is one of the criticisms. If decisions are made behind a closed door then this leads to abuse (eg. blocking political speech). Need public scrutiny and pressure to keep it in line. Taking a non-consequential ethical approach we need transparency for this scheme to meet the ethical principles of openness, fairness, honesty, integrity and so on. From a consequential approach, much research would need to be undertaken to consider the consequences, and this is something the governments reports should address. With the research in hand and from a utilitarian approach would censorship with no transparency produce the most happiness, or from an epistemic approach would this case of censorship without transparency really advance knowledge more than no censorship or censorship with transparency?
- This is real and at the end of the day it is computer scientists or software engineers that will implement any censorship. As such in the end it will come to these people to make an ethical decision on whether what they are doing is ethically right under their principles.
A social issue is over-legislating. eg. . For example certain materials (which probably includes child pornography) is illegal to view, so if you happen to accidentally find this material on the internet and you want to report it to the police so they can track down the perpetrator, you are in a conundrum. If you tell the police about it, then you must have viewed the material yourself which is illegal so you may face criminal charges, hence you cannot report it.
Another social issue. Is it just illegal content? Should the government be deciding what to view or not?
Technical Issue. What about things like VPN’s, tor…? The internet is huge and dynamic? What about a tag system.
COMP2121 Quick Summary on Particular Aspects
Von-Newman vs. Harvard Architecture.
Von-Newman has a single memory space, share for data and program instructions. Harvard Architecture has separate memory spaces for data and instructions (so you cannot execute from the data memory).
2’s compliment

It is important to know that the hardware does all arithmetic in 2’s compliment. It is up to the programmer to interpret the number as signed or unsigned.
To convert a number from 2’s compliment, for example -45 in 2’s compliment is 11010011, we can do something like this,

To go the other way from say -1 to the 2’s compliment form 11111111 we use that 
If the number you wish to convert is negative, let 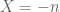

Now that was complicated. But its the only way I can get that advertised
Sign Extension
Why do we need sign extension? We need it in order to do operations on numbers than have different bit lengths (the number of bits used to represent the number).
Decimal to Binary
From a human kind of approach to convert 221 to binary, we see that 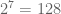
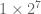



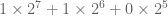


We can convert hexadecimal to binary by going from hex to decimal then decimal to binary. For hex to decimal,
(where F23AC is in hex and 992172 is in decimal)
Operations on Signed and Unsigned Multi byte Numbers
add al, bl adc ah, bh does a + b, result in is a.
There are 3 multiplication operations, MUL (Multiply Unsigned), MULS (Multiply Signed) and MULSU (Multiply Signed with Unsigned). They each do this. Notice the result is stored in r1:r0.
 Thus to do n*m = r where n is 2 bytes unsigned and m is 1 byte signed,
mulsu nl, m ;nl * (signed)m
movw rh:rl, r1:r0
mulsu nh, m ;(signed)nh * m
add rh, r0
Thus to do n*m = r where n is 2 bytes unsigned and m is 1 byte signed,
mulsu nl, m ;nl * (signed)m
movw rh:rl, r1:r0
mulsu nh, m ;(signed)nh * m
add rh, r0
We can also do 16bit * 16bit,
;* From AVR Instruction Set Guide, pg 99-100. ;* Signed multiply of two 16-bit numbers with 32-bit result. ;* r19:r18:r17:r16 = r23:r22 * r21:r20 muls16x16_32: clr r2 muls r23, r21 ;(signed)ah * (signed)bh movw r19:r18, r1:r0 mul r22, r20 ;al * bl movw r17:r16, r1:r0 mulsu r23, r20 ;(signed)ah * bl sbc r19, r2 add r17, r0 adc r18, r1 adc r19, r2 mulsu r21, r22 ;(signed)bh * al sbc r19, r2 add r17, r0 adc r18, r1 adc r19, r2 ret
brge and brsh
- brge is Branch if Greater or Equal, Signed.
if () then branch.
When you do cp Rd, Rr then brge, the branch will be taken if RdRr, where Rd and Rr are taken to be signed numbers.
- brsh is Branch if Same or Higher.
if () then branch.
When you do cp Rd, Rr then brsh, the branch will be taken if Rd
Calculating Total Stack Space Needed
Draw a call tree, find the path with the most total weight, that total weight is the total stack size needed. Here is the sample question,
A C program consists of five functions. Their calling relations are shown as follows (the arguments and irrelevant C statements are omitted).
int main(void) {…func1(…);func2(…);…}int func1(…) { … func1(…); … } int func2(…) { … func3(…); func4(…); … }func1() is a recursive function and calls itself 15 times for the actual parameters given in main(). Both func3() and func4() do not call any function. The sizes of all stack frames are shown as follows.
main(): 200 bytes.
func1(): 100 bytes.
func2(): 400 bytes.
func3(): 1,400 bytes.
func4(): 300 bytes.How much stack space is needed to execute this program correctly? (3 marks)
 There are three paths,
There are three paths,
| main() func1() func1() x 15 200+100+15×100 =1800 |
main() func2() func3() 200+400+1400 =2000 |
main() func2() func4() 200+400+300 =900 |
The path with the most total weight is main() > func2() > func3(), so this is the total stack space needed.
Nested Interrupts
 (Source: Hui Wu’s Lecture Notes)
(Source: Hui Wu’s Lecture Notes)
Keypads with ‘abc’ ‘def’ … buttons
These keypads where to enter b you need to press the abc button twice in succession, but wait to long at it will chose a. Here is a psudo algorithm that seemed to fit this,
.def reg = rN
.def reg = rM
.def count = rX
//passvalue means that we register the given value ie. abc abc wait > b
setup:
clr reg (to some value that is != to a key value) ;set to default
clr count
rjmp keyloop
keyloop:
check pins for a key
if no key pressed rjmp keyloop, else continue
//key was pressed, and value is stored in key
reset someTimeCounter
if (key == reg) {
inc count
if (count == 3)
passvalue(reg,count)
}else{
if (reg != default) ;so we don't initially passvalue
passvalue(reg,count) ;send the last value
reg = key ;store the new one
count = 1
}
rjmp keyloop
if someTimeCounter expires and count != 0 //(count up, so expires after time to wait for anymore keypresses) (check count != 0, because if its 0 then we never had any key pressed that we need to send)
passvalue(reg,count)
reg = default
Switch Bounce Software Solution
When a switch makes contact, its mechanical springiness will cause the contact to bounce, or make and break, for a few millisecond (typically 5 to 10 ms). Two software solutions are wait and see and counter-based.
- If we detect it as closed, wait for a little bit and check again.
- Poll the switch constantly. For each poll if the switch is closed increment the counter. If we reach a certain value in a certain time then the switch was closed (or button pressed).
Serial Communication (Start and Stop bit)
“[The] start bit is used to indicate the start of a frame. Without the start bit, the receiver cannot distinguish between the idle line and the 1 bit because both are logical one. A stop bit is used to allow the receiver to transfer the data from the receive buffer to the memory.” (Wu, Homework 6 Solutions)
UART
 (Source: Hui Wu, Lecture Notes)
(Source: Hui Wu, Lecture Notes)
Sample Q3a
(This code probably won’t work and probably has errors (and maybe not just simple ones, but serious ones that mean that the logic is wrong))
.dseg A: .byte 20 ;array of size 10, element size 2 bytes .cseg ldi XL, low(A) ldi XH, high(A) ;add the contents of the array. store 0 store 1 store 2 store 3 store 4 store 5 store 6 store 7 store 8 store 9 ;find the largest value ldi XL, low(A) ldi XH, high(A) ;start with the 1st element of the array ld r25, X+ ld r26, X+ ldi r20, 10 ;size of array loop: cpi r20, 0 breq endloop ld r21, X+ ld r22, X+ cp r25, r21 cpc r26, c22 brlo lowerthan ;we have a new max mov r25, r21 mov r26, r22 lowerthan: inc r20 rjmp loop endloop: rjmp endloop .macro store ldi r16, low(@0) ldi r17, high(@0) st X+, r16 st X+, r17 .endmacro
For some reason in my lecture notes I have “eg. fine 2nd or 3rd smallest or largest” so here is a modification to do something like that.
.dseg A: .byte 20 ;array of size 10, element size 2 bytes .cseg ldi XL, low(A) ldi XH, high(A) ;add the contents of the array. store 0 store 1 store 2 store 3 store 4 store 5 store 6 store 7 store 8 store 9 ;sort into accending loopthough for the length of array, (by then we can be sure its sorted) ldi r23, 10 largeloop: cpi r23, 0 breq endlargeloop ;point X to the start of A ldi XL, low(A) ldi XH, high(A) ;start with the 1st element of the array ld r25, X+ ld r26, X+ ldi r20, 10 ;size of array loop: cpi r20, 0 breq endloop ;the next value ld r21, X+ ld r22, X+ cp r25, r21 cpc r26, c22 brge gethan ;r22:r21 < r26:r25 ;swap the order st -X, r26 st -X, r25 st -X, r22 st -X, r21 ld r24, X+ ;to change the X pointer ld r24, X+ ld r25, X+ ld r26, X+ gethan: inc r20 rjmp loop endloop: endlargeloop: inf: rjmp inf .macro store ldi r16, low(@0) ldi r17, high(@0) st X+, r16 st X+, r17 .endmacro
 Google Reader Shared Items
Google Reader Shared Items
- An error has occurred; the feed is probably down. Try again later.
License

The content on this blog by Andrew Harvey, unless otherwise noted is licensed under a Creative Commons Attribution-Share Alike 3.0 Australia License.

{kind=link}
{kind=link}
{kind=link}